시작하며

우리는 저번 포스팅에서 Overfitting을 다루며 배웠던 'non-linear classification' 에서, feature가 두개일 때 위와 같이 Decision Boundary를 표현해보았습니다..
[머신러닝] 모델의 과적합(Overfitting)을 피하기 위한 방법
시작하며 우리는 지금까지 Linear Regression 그리고 Logistic Regression 두가지에 중점을 두어 Supervised Learning을 공부하였습니다. 이번 포스팅에서는 모델 학습 과정에서 발생할 수 있는 'Overfitting' 이..
box-world.tistory.com
이번 포스팅은 Logistic Regression을 이해하고 보시면 더욱 효과적입니다.
[머신러닝] Logistic Regression 이해하기 1
https://box-world.tistory.com/13?category=397062
[머신러닝] Logistic Regression 이해하기 1
시작하며 우리는 그동안 Supervised Learning 에서 회귀(Regression) 를 중점적으로 다뤘습니다. 이때 회귀 란 결과값을 예측하는 것이었습니다. 이제부터는 마찬가지로 Supervised Learning 중 하나인 분류(Class..
box-world.tistory.com
[머신러닝] Logistic Regression 이해하기 2
https://box-world.tistory.com/14?category=397062
[머신러닝] Logistic Regression 이해하기 2
시작하며 저번 포스팅에선 Supervised Learning 중 하나인 Classification 에 대해 알아보고, 여기에 사용되는 Logistic Regression 의 기초를 공부하였습니다. Logistic Regression 이해하기 1 https://box-worl..
box-world.tistory.com

그런데 만약 feature가 100개인 dataset에 대해 가설함수 h를 2차방정식으로 놓게되면, 가설함수의 각 항은 X1^2θ, X1X2θ, X1X3θ ... X1X100θ 으로 5000개 가 됩니다.

만약 h 함수가 3차 방정식 이라면 (n^3 / 3!)으로 features의 수는 170000개가 됩니다. 즉 feature가 n개인 dataset에 대해 k차 가설함수를 설정하면 항의 갯수는 (n^k / k) 가 됩니다.
주목해야할 것은, feature가 많은 dataset에 대해, Logistic Regression으로 항의 개수가 5000개, 1700000개 되는 가설함수를 g로 감싸 값을 도출한다는 것은 매우 비효율적인 일입니다.
하지만 Neural Network 는 이러한 상황에 제약을 받지 않습니다. 왜 그런지 그리고 Neural Network란 무엇인지 앞으로 여러 포스팅에 걸쳐 공부해보겠습니다.
Neural Netwrok란?

Neural Network(인공신경망) 은 실제 인간의 뇌 신경망을 모방한 것입니다. Deep Learning 은 이를 이용한 ''알고리즘''으로 머신러닝을 최종적으로 실현하는 것입니다.

인간의 뇌 속에는 1000억 이상의 뉴런(신경세포)이 100조 이상의 시냅스 를 통해 병렬적으로 연결되어 있습니다.
각 뉴런은 수상돌기(입력) 를 통해 다른 뉴런에서 신호를 받아 축삭돌기(출력) 에서 다른 뉴런으로 신호를 보냅니다.
이때 출력으로 내보내는 신호는 입력 신호가 모여 일정 용량을 넘어서면 일어나게 됩니다.
이러한 뉴런이 연결되어 있는 뇌 는 물리적으로 근접한 어떤 방향의 뉴런이든 상호 연결이 가능합니다.
하지만 인공신경망의 경우 에는 연결되는 방향과 데이터가 흘러가는 방향이 일정하다는 점에서 차이가 있습니다.
초기에는 아주 기본적인 신경망에도 많은 연산이 요구되어 상용화에 어려움을 겪었으나, 지금은 GPU의 발전 으로 딥러닝의 발전은 점점 더 가속화 되고 있습니다.
Neural Network을 구성하는 요소들
이제 Neural Network가 어떻게 구성되는지 알아보겠습니다.

우선 Neural Network에서 Logistic Unit이 우리 뇌의 뉴런에 해당됩니다. 이때 '하나의 Unit'에서는 '한번의 Logistic Regression'이 발생하여 h(x)값을 내보냅니다.
뉴런에서 입력을 받아 출력을 내보내던 것이 위 이미지에서 하나의 Logistic Unit에서 x1,x2,x3 3개의 input 을 받은 후, h(x) 값을 내보내는 것으로 표현이 가능합니다. 이때 x0(=1)은 상수로 bias unit 이라고 하며 큰 의미는 없습니다.
참고로 Neural Network에선 'sigmoid(logistic)함수 g' 를 activation function 이라고 보통 부르며, θ 는 Weight 를 뜻하는 W로 표기하기도 합니다.

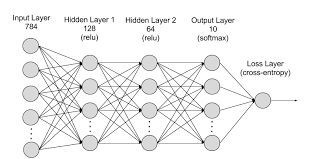
이번엔 중간에 한줄이 추가되었습니다. 이렇게 Neural Network에선 동일선상에 있는 하나의 세로 줄을 'Layer' 라고 합니다.
이때 가장 왼쪽에서 input을 받는 Layer를 Input Layer, 가장 오른쪽에서 output을 보내는 Layer를 output Layer, 그리고 가운데 있는 Layer를 Hidden Layer 라고 부릅니다.
이때 Layer의 수가 몇개이건 왼쪽의 Input Layer와 오른쪽 Output Layer를 제외한 나머지 가운데 Layer들은 모두 'Hidden Layer' 입니다.

이번엔 Neural Network(NN)를 수식으로 들여다보겠습니다. 위 NN은 각각 3개의 unit을 가진 3개의 Layer로 구성되어 있습니다.
가운데 3개의 unit은 activation unit이란 뜻에서 'a' 로 표현하며, Input 데이터에 곱해질 가중치(Weight)는 'θ'로 표현합니다.* 이제 데이터의 흐름을 살펴보겠습니다.
Hiddent Layer의 각 activation unit은 Input Layer 내 3개의 x값을 Input으로 하여 도출한 H(x)값을 Output Layer로 보냅니다. 그리고 Output Layer는 각 activation unit에서 보낸 3개의 H(x)값을 Input으로 하여 H(x)값을 도출하게 되는 구조입니다.

이때 j번째 Layer가 J개의 unit S을 가지고 있었는데 j+1번째 unit이 j+1개의 unit S을 가지게 된다면 이때 가중치를 나열한 Matrix θj는 Sj+1 x (Sj + 1)차원이 됩니다.

이때 Input layer부터 output layer까지 순서대로 변수들을 계산하고 저장하는 것 즉 데이터 계산의 흐름이 위에서 설명한 것과 같이 왼쪽에서 오른쪽으로 가는 것을 'Forward Propagation' 이라고 합니다.
이를 언급하는 이유는 후에 나올 중요한 'Back Propagation' 을 배울 때 대조되는 개념이기 때문입니다.
Forward Propagation일 경우, Layer 2의 각 unit은 input xi에 θ를 곱하여 더한 값을 가집니다. 이때 (θ*xi) = z 라 놓았을 때 a2(2)는 g(z(2))라 표현할 수 있으며 이것이 각 unit에서 내보내는 결과값이 됩니다.

그렇게 Layer 2의 각 unit에서 연산된 값들은 Output Layer인 Layer 3에 전해져 최종적인 h(x) 함수로 처리되고 이때 나온 h(x)는 g함수에 감싸져 0과 1 중 어느 값을 최종적인 출력값으로 내놓을지 정합니다.

Neural Network에는 Input Layer와 Output Layer는 존재해야 한다는 점 빼고는 unit의 크기나 Layer의 구성이 자유롭습니다.
그래서 Neural Network를 활용함에 있어서 가장 중요한 것중 하나는 이러한 Network의 architecture(설계) 을 어떻게 짜느냐 입니다.
요약
1) Neural Network(인공신경망) 은 실제 인간의 뇌 신경망을 모방한 것입니다. Deep Learning 은 이를 이용한 ''알고리즘''으로 머신러닝을 최종적으로 실현하는 것입니다.
2) Neural Network는 여러개의 Logistic Unit 으로 구성되는데, '하나의 Unit'에서는 '한번의 Logistic Regression'이 발생하여 g(h(x))값을 내보냅니다.
3) Neural Network에선 동일선상에 있는 하나의 세로 줄을 'Layer' 라고 합니다.
4) Input layer부터 output layer까지 순서대로 변수들을 계산하고 저장하는 것을 'Forward Propagation' 이라고 합니다.
5) 전체적인 Neural Network의 동작방식
* Input Layer를 통해 데이터를 받는다.
* 각 unit에선 g(h(x)) 값을 그 다음 Layer로 보낸다.
* 최종적인 Output Layer에서 도출한 h(x)값을 g 함수로 감싸 Classification에 대한 결과값을 도출한다. ex) 0 or 1
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [머신러닝] Back Propagation(역전파) 정복하기 (0) | 2020.05.01 |
|---|---|
| [머신러닝] Neural Network를 이용한 XNOR 연산 그리고 Multi Classification (0) | 2020.05.01 |
| [머신러닝] 모델의 과적합(Overfitting)을 피하기 위한 방법 (2) | 2020.04.30 |
| [머신러닝] 여러 개로 분류하기(Multi Classification) (1) | 2020.04.30 |
| [머신러닝] Logistic Regression 이해하기 2 (1) | 2020.04.30 |