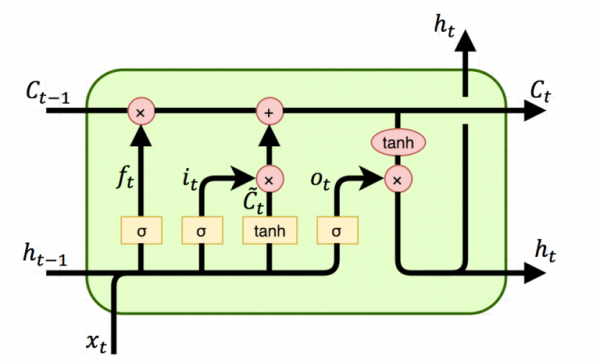
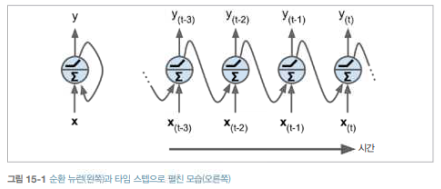
아무리 어려워도 한번 시작한 일은 끝까지 해라 - 안드레아 정 (에어본 회장) - 저번 포스팅에서 우리는 RNN을 이용하여 주어진 Time-Series 데이터를 이용하여 미래를 예측하는 forecasting에 대해 공부해보았습니다. 하지만 이전에 우리가 다뤘던 데이터들의 길이는 상대적으로 짧은 축에 속했습니다. 몇달이 아닌 몇 년 치의 데이터에도 RNN은 좋은 성능을 보일까요? 긴 시퀀스(상대적으로 많은 타임 스텝을 가지는 Time-Series Data)로 훈련하려면 많은 타임 스텝에 걸쳐 실행해야 하므로 RNN은 그만큼 매우 깊은 네트워크가 됩니다. 보통 이렇게 깊어진 RNN은 다음과 같은 문제가 발생할 수 있습니다. 깊어진만큼 Gradient Vanishing 문제나 Exploding 문제가 발생할 ..