저번 포스팅에서는 캘리포니아 주택 가격 데이터셋을 가지고 pandas, sklearn을 이용하여 데이터의 특성을 탐색하고, 모델 학습을 위해 test set을 분리하는 다양한 방법에 대해 알아보았습니다.
이번 포스팅에서는 데이터를 탐색하고 시각화하는 것부터 데이터를 전처리 하는 과정까지 다뤄보도록 하겠습니다.
[ 핸즈 온 머신러닝 2판 ] pandas, sklearn을 통한 데이터 전처리는 어떻게 하는걸까? (1)
발견에는 항상 뜻밖의 재미가 있다 - 제프 베조스(Amazon CEO) - Chapter 2 이번 포스팅을 시작으로 3번에 걸쳐 하나의 머신러닝 프로젝트가 어떻게 구성되고 진행되는지 알아보겠습니다. 우선 주요 단
box-world.tistory.com
2.4 데이터 이해를 위한 탐색과 시각화
우선 데이터셋에서 training set만 떼서 탐색을 진행하겠습니다. 보통 데이터가 크다면 training set 중에서도 일부를 떼어 탐색용 subset을 만들기도 하지만 우리는 전체 training set을 사용하겠습니다.
housing = strat_train_set.copy()2.4.1 지리적 데이터 시각화
데이터셋에 위도(longitude)와 경도(latitude)에 해당하는 지리정보가 있으므로 이를 산점도(Scatter)를 이용하여 시각화하겠습니다. 산점도란 두개 변수간의 관계를 직교 좌표계 위에 나타낸 그래프를 의미합니다.

위 그림 자체로는 특별한 패턴을 찾기 어려울 것입니다. 여기에 alpha 옵션을 주면 군집도를 통해 패턴을 찾아낼 수 있습니다.

이제 여기에 주택 가격을 나타내보겠습니다. 원의 반지름은 구역의 인구, 그리고 파란색에서 빨간색으로 갈수록 높은 가격을 가지는데 이를 함수에서 cmpa = get_cmap("jet")로 표현합니다.
그래프를 보면 인구 밀도와 주택 가격이 밀접하게 관련되어 있다는 것을 알 수 있습니다.

2.4.2 상관관계 조사
데이터셋이 너무 크지 않기 때문에 feature 간의 표준 상관계수(Standard correlation coefficient)를 corr() 함수를 이용해 쉽게 계산할 수 있습니다.
corr_matrix = housing.corr()이제 중간 주택 가격(median_house_value)와 다른 특성 간의 상관관계의 크기에 대해 알아보겠습니다. 상관관계의 범위는 (-1,1) 사이이며 1에 가까울수록 강한 양의 상관관계를 의미합니다. 그리고 0에 가까울수록 선형적인 상관관계가 없다고 할 수 있습니다.
- 중간 주택 관계와 위도는 약한 음의 상관관계를 보입니다.

다음은 두 변수간에 가질 수 있는 다양한 상관관계의 형태를 보여줍니다. 주의할 것은 우리가 위에서 확인한 상관계수는 선형적인 상관관계만 측정합니다. 즉 아래 세번째 줄과 같은 비선형적인 상관관계는 잡지 못하고 0에 가까운 값으로 도출되게 됩니다.

feature간 상관관계를 확인하는 또 다른 방법은 pandas의 scatter_matrix를 이용하여 숫자형 특성 사이에 산점도를 그리는 것입니다. 아래서 그 일부를 보도록 하겠습니다.
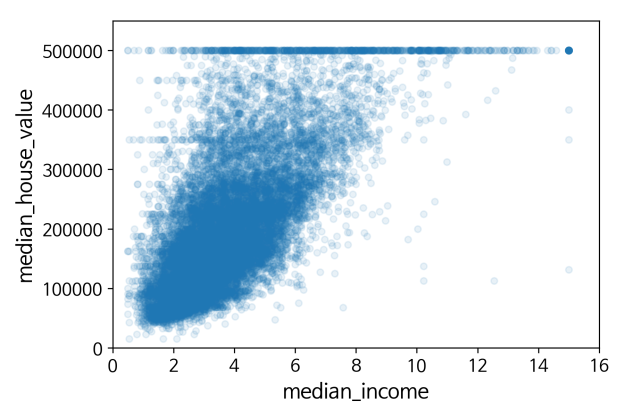
왼쪽 위에서 오른쪽 아래로가는 대각선은 자기 자신에 대한 상관관계이므로 직선이 되는 것이기에 무시하셔도 됩니다. 아래에서 우리가 주목할 것은 첫번째 줄의 두번째 그래프인 중간 소득(median_income)과 중간 주택 가격의 관계이니 이를 확대에서 다시 살펴보겠습니다.
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12,8))
- 중간 소득이 커질수록 중간 주택 가격이 상승하는 강한 상관관계를 보여주며, 포인트들이 너무 멀리 퍼져있지 않습니다.
- 중간 주택 가격이 500000인 부분에서 수평선이 나타나는 이유는 가격 제한을 500000 이하로 두었기 때문입니다. 이 외에 350000, 280000에서 보이는 수평선은 면밀히 살펴보고 이상한 형태의 학습이 있었다면 이를 지워야 합니다.
2.4.3 feature 조합으로 실험
모델 학습을 위해 데이터를 준비하는 과정에서 마지막으로 해볼 수 잇는 것은 여러 feature 조합을 시도해보는 것입니다. 이 부분에 대해서는 단순히 코딩이 아니라 feature간의 의미를 생각하며 어떤 features를 결합해야 유의미한 결과를 얻을 수 있을지 생각해야 합니다.
예를 들어 특정 구역의 방 개수 자체는 해당 지역의 가구 수를 모른다면 의미가 없을 것입니다. 이렇나 맥락에서 가구당 방 개수를 도출해볼 수 있습니다. 다음에서 이런 특성들을 만들어 corr_matrix를 확인해보겠습니다.
- 새롭게 추가한 bedrooms_per_room은 total_bedrooms나 total_rooms보다 중간 주택 가격과의 상관관계가 훨씬 높습니다.
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
###결과값###
>>
median_house_value 1.000000
median_income 0.687160
rooms_per_household 0.146285
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population_per_household -0.021985
population -0.026920
longitude -0.047432
latitude -0.142724
bedrooms_per_room -0.259984
Name: median_house_value, dtype: float64지금까지 데이터를 탐색하는 몇 단계를 거쳐보았습니다. 하지만 머신러닝에서는 한번에 끝나는 일은 잘 없습니다. 최대한 빨리 이러한 프로토타입을 만들어 데이터에 대한 통찰을 얻고, 다시 이러한 과정을 반복하며 유의미한 결과를 계속해서 뽑아내는 과정을 거쳐야 합니다.
2.5 머신러닝 알고리즘을 위한 데이터 준비
이제 머신러닝 알고리즘을 위해 데이터를 만들어 보겠습니다. 중요한 것은 이러한 작업은 자동화되어야 하는데 다음은 그 이유입니다.
- 어떤 데이터셋이 주어져도 쉽게 데이터를 변환할 수 있습니다.
- 프로젝트에서 앞으로 사용할 다양한 변환 라이브러리로 활용될 수 있습니다.
- 여러 가지 데이터 변환을 쉽게 하며 어떤 조합이 가장 좋은지 확인하는데 편리합니다.
우선 앞서서 생성한 strat_train_set에서 데이터 변형이 label에도 적용되는 것을 방지하기 위해 label인 median_house_value를 training set에서 분리하겠습니다.
housing = strat_train_set.drop("median_house_value",axis=1)
housing_labels = strat_train_set["median_house_value"].copy()2.5.1 데이터 정제
데이터 정제란 전처리가 완료된 데이터에 대해 빈값(결측치)이나 정상 범위를 벗어난 값(이상치)들을 제거하거나 다른 값으로 대체하는 처리 과정을 의미합니다.
우선 앞서서 total_bedrooms에 누락된 값이 있었습니다. 누락된 값은 다음 세 가지 방식으로 처리할 수 있습니다.
- 해당 구역을 제거하기
- 전체 feature 삭제
- 특정 값을 채우기(0, median, mean etc...)
이러한 작업은 pandas의 2차원 테이블 구조인 DataFrame의 다양한 메서드를 이용하여 간단하게 처리가 가능합니다.
housing.dropna(subset=["total_bedrooms"]) # 누락된 데이터가 들어있는 구역은 제거
housing.drop("total_bedrooms",axis=1) # feature 삭제
median = housing["total_bedrooms"].median() # median으로 채우기
housing["total_bedrooms"].fillna(median,inplace = True)혹은 sklearn의 SimpleImputer로 누락된 값을 다룰 수 있습니다. strategy = "median"으로 누락된 값을 중간값으로 대체할 것을 지정합니다.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")SimpleImputer를 적용하기 앞서 수치형(categorical) 특성인 ocean_proximity를 제외한 복사본에 적용하겠습니다.
housing_num = housing.drop("ocean_proximity",axis=1)이제 imputer에 데이터셋을 인자로 주면 각 feature의 median을 statistics_ 속성에 저장합니다.
imputer.fit(housing_num)
imputer.statistics_
###결과값###
>> array([ -118.51 , 34.26 , 29. , 2119.5 , 433. , 1164. , 408. , 3.5409])마지막으로 transform() 메서드로 데이터셋에 적용해주면 됩니다.
X = imputer.transform(housing_num)X는 numpy 배열입니다. 이를 다시 pandas DataFrame으로 되돌릴 수 있습니다.
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index = housing_num.index)좀 더 공부하기에 앞서 sklearn의 'estimator'와 'trasformer' 개념에 대해서 간단히 짚고 가겠습니다.
estimator는 input data에서 새롭게 추정된 데이터로 fit() 메서드가 사용됩니다. transformer는 input data를 변형하며 transform() 메서드가 사용됩니다. 예를 들어 앞서 사용한 imputer 객체는 estimator, imputer 자체는 transformer라고 할 수 있습니다.
2.5.2 텍스트와 범주형 특성 다루기
이제 수치형 feature가 아닌 유일한 categorical feature인 ocean_proximity에 대해 다뤄보겠습니다. 우선 처음 10개 데이터에서 이 feature 값을 확인해보겠습니다.
housing_cat = housing[["ocean_proximity"]]
housing_cat.head(10)
###결과값###
>>
17606 <1H OCEAN
18632 <1H OCEAN
14650 NEAR OCEAN
3230 INLAND
3555 <1H OCEAN
19480 INLAND
8879 <1H OCEAN
13685 INLAND
4937 <1H OCEAN
4861 <1H OCEAN대부분의 머신러닝 알고리즘은 숫자를 다루기 때문에 이러한 categorical feature는 텍스트에서 숫자로 바꿔줄 필요가 있습니다. 이를 위해 sklearn의 OridinalEncoder 클래스를 사용합니다.
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded[:10]
###결과값###
>>
array([[0.],
[0.],
[4.],
[1.],
[0.],
[1.],
[0.],
[1.],
[0.],
[0.]])그리고 이렇게 변환된 array에서 categories_ 인스턴스 변수를 이용하면 카테고리 목록 확인이 가능합니다.
ordinal_encoder.categories_
###결과값###
>>
[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],
dtype=object)]위 표현 방식의 문제점은 알고리즘이 가까이 있는 두값이 떨어져있는 두 값보다 더 비슷하다고 생각한다는 점입니다(['bad', 'average', 'good', 'excellent']와 같은 경우).
그래서 대부분의 categorical feature에 대해 숫자로 변환할 때는 one-hot encoding 방식을 사용합니다. 예를 들어 카테고리가 <1H OCEAN>이라면 이는 1을 가지고 나머지 feature는 모두 0을 가지는 벡터가 해당 데이터가 어느 카테고리에 속하는지 표현하는 방식이 되는 것입니다.
이때 출력은 numpy array가 아니라 sparse matrix라는데 주목해야합니다. 즉 앞서 말했던 하나만 1이고 나머지는 0으로 채워져있는 벡터의 형태를 의미하는 것이빈다. 그러나 0을 모두 메모리에 저장하는 것은 비효율적이므로 sparse index는 0이 아닌 원소의 위치만을 저장합니다.
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot
###결과값###
>>
<16512x5 sparse matrix of type '<class 'numpy.float64'>'
with 16512 stored elements in Compressed Sparse Row format>이를 numpy 배열로 바꾸고 싶다면 다음과 같이 할 수 있습니다.
housing_cat_1hot.toarray()
###결과값###
>>
array([[1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1.],
...,
[0., 1., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.]])이렇게 변환한 numpy 배열에서도 categories_ 인스턴스 변수가 적용됩니다.
cat_encoder.categories_
###결과값###
>>
[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],
dtype=object)]2.5.3 나만의 변환기
sklearn이 유용한 transformer를 제공하지만, 상황에 따라 특정 작업을 위해 우리가 직접 transformer를 만들어야 할수도 있습니다. 이를 위해 내가 만든 transformer가 sklearn과 매끄럽게 연동되길 원한다면 fit(), transform(), fit_transform() 메서드가 구현된 클래스를 만들면 됩니다. 다음은 간단한 변환기입니다.
아래는 transformer가 add_bedrooms_per_room 하이퍼파라미터를 하나 가지며 기본값은 True입니다.
from sklearn.base import BaseEstimator, TransformerMixin
rooms_ix, bedrooms_ix, population_ix, households_ix = 3,4,5,6
class CombineAttirbutesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True):
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:,bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombineAttirbutesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)2.5.4 특성 스케일링
가장 중요한 데이터 처리 과정 중 하나가 feature scaling입니다. 왜냐면 머신러닝 알고리즘은 feature들의 input data의 범위(scale)이 다르면 잘 작동하지 않기 때문입니다. 우리의 데이터셋의 경우 전체 방 개수의 범위는 6~39320인 것에 비해 median_income은 0~15입니다.
scaling에는 보통 min-max scaling(normalization)과 표준화(standardization)이 사용됩니다.
min-max scaling은 데이터가 0~1 범위에 들도록 스케일을 조정해줍니다. sklearn에서는 'MinMaxScaler' transformer를 제공합니다. 다른 범위를 사용하고 싶다면 feature_range 매개변수로 조정하면 되겠습니다.
표준화는 분산이 1이 되도록 합니다. 이는 min-max scaling에서의 0~1과 같은 범위은 상한, 하한이 없어 특정 알고리즘에서는 문제가 될 수 있습니다. 그러나 표준화는 '이상치'에 영향을 덜 받습니다. sklearn에서는 'StndardScaler' transformer를 표준화를 위해 제공합니다.
2.5.5. Transform 파이프라인
transform 단계가 여러개라면 그 순서는 더욱 중요할 수 밖에 없습니다. sklearn에서는 이러한 연속된 변환이 순서대로 안정적으로 이뤄지도록 Pipeline 클래스를 통해 지원해줍니다. 다음은 숫자형 feature를 처리하는 파이프라인입니다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([('imputer',SimpleImputer(strategy="median")),
('attribs_adder', CombineAttirbutesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)Pipeline은 연속된 단계를 나타내는 (이름 / estimator) 쌍의 목록을 입력으로 받습니다. 이때 마지막 단계를 제외하고는 나머지 단계에서는 transformer만 사용이 가능합니다. 즉 fit_transform() 메서드를 가지고 있어야 합니다.
파이프라인의 fit() 메서도를 호출하면 내부의 모든 transformer의 fit_transform() 메서드를 순서대로 호출하면서 한 단계의 출력을 다음 단계의 입력으로 전달합니다. 마지막 단계에서는 fit() 메서드만 호출합니다.
파이프라인 객체는 마지막 estimator와 동일한 메서드를 제공합니다. 위 예에서는 StandardScaler가 마지막 단계이므로 파이프라인은 transform() 메서드를 가지고 있습니다.
지금까지는 categorical feature와 수치형 feature를 따로 다뤘습니다. 그러나 하나의 transformer로 categorical과 수치형을 동시에 처리할 수 있다면 훨씬 편할 것입니다. sklearn에서는 ColumnTransformer를 통해 이를 지원합니다. 이는 pandas DataFrame과 잘 동작합니다.
- 우선 수치형 열, 범주형 열 리스트를 각각 만들어줍니다.
- 그 다음 ColumnTransformer의 생성자에서는 (이름, transformer, transformer에 적용될 리스트)를 각 튜플마다 받습니다.
- 이때 OneHotEncoder는 대부분이 0으로 구성된 Sparse Matrix를, num_pipeline은 대부분이 0이 아닌 값으로 구성된 Dense Matrix를 반환합니다. 이렇게 두가지가 섞여있을 때 ColumnTransformer는 최종 Matrix에서 0이 아닌 값에 대한 비율을 분석하여 30% 이하이면 Sparse를 그렇지 않으면 Dense를 반환합니다. (기본적으로 sparse_threshold = 0.3)
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([("num", num_pipeline, num_attribs),
("cat",OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)이러헥 해서 우리는 전체 주택 데이터를 받아 적절한 변환을 적용하는 파이프라인을 만들었습니다.
다음 포스팅에서는 전처리한 데이터를 이용해 모델을 선택하고 훈련하여 튜닝하는 단계에 대해 다뤄보겠습니다. 오늘도 행복한 하루 보내시길 바랍니다 :)
[ 핸즈 온 머신러닝 2판 ] pandas, sklearn을 통한 모델 학습과 튜닝은 어떻게 하는 것일까? (3)
이전 2개의 포스팅에 결쳐 우리는 지금까지 문제를 정의하고 데이터를 읽어들여 탐색하였습니다. 그리고 데이터를 training set과 test set으로 나누고 학습을 위한 머신러닝 알고리즘에 주입할 데�
box-world.tistory.com
'AI > Hands-On Machine Learning 2판' 카테고리의 다른 글
| [핸즈온 머신러닝 2판 ] MNIST를 활용한 다중 분류(Multi Class Classification)은 어떻게 하는 것일까? (1) | 2020.07.20 |
|---|---|
| [핸즈온 머신러닝 2판] MNIST를 활용한 이진 분류(Binary Classification)은 어떻게 하는 것일까? (4) | 2020.07.19 |
| [ 핸즈 온 머신러닝 2판 ] pandas, sklearn을 통한 모델 학습과 튜닝은 어떻게 하는 것일까? (3) (0) | 2020.07.16 |
| [ 핸즈 온 머신러닝 2판 ] pandas, sklearn을 통한 데이터 전처리는 어떻게 하는걸까? (1) (0) | 2020.06.09 |
| [핸즈 온 머신러닝] 머신러닝(Machine Learning)의 종류와 유의할 점 (1) | 2020.06.02 |