무언가가 충분히 중요하다면 확률이 당신에게 유리하지 않더라도 시작하라
- 일론 머스크 -
Introduction:

ChatGPT 같은 AI 모델이 이전 대화 내용을 기억하는 것처럼 보이는 게 신기하지 않으셨나요? 마치 진짜 기억력이 있는 것 같죠! 하지만 기존 AI 모델, 특히 엄청나게 강력한 Transformer 모델들은 사실 기억력에 약간 문제가 있습니다. 엄청나게 큰 책을 읽으려고 하는데 한 번에 몇 페이지만 집중할 수 있는 상황이라고 생각해보세요. Transformer의 "attention" 메커니즘이 대단하긴 하지만, 너무 많은 걸 기억하려고 하면 속도가 느려지고 엄청난 컴퓨팅 파워를 잡아먹거든요. 이 논문에서는 "Titans"라는 새로운 종류의 AI 아키텍처를 소개합니다. 이 녀석은 방대한 양의 정보를 다룰 때도 효과적으로 기억하는 방법을 스스로 학습하도록 설계되었죠. AI 모델에게 우리처럼 더 나은 장기 기억 능력을 부여하는 거라고 보시면 됩니다!
Motivation & Contribution:
그럼 AI에게 기억력이 왜 그렇게 중요할까요? 만약 영화의 마지막 몇 장면만 기억할 수 있다면 전체 줄거리를 이해할 수 있을까요? 연결고리나 큰 그림을 놓치게 되겠죠. 마찬가지로, AI가 긴 이야기, 비디오, 심지어 시간의 흐름에 따른 과학 데이터 같은 복잡한 데이터를 제대로 이해하려면, 최근 정보뿐만 아니라 훨씬 이전의 정보도 기억해야 합니다.
문제점: 현대 AI의 핵심인 Transformer는 제한된 "context window" 내에서 관계를 파악하는 데는 환상적입니다. 마치 책의 몇 페이지처럼요. 하지만 context가 책 전체처럼 엄청 길어지면, Transformer는 힘들어합니다. 속도가 느려지고 엄청난 컴퓨터 메모리를 필요로 하죠. 왜냐하면 Transformer의 attention 메커니즘은 quadratic cost를 갖기 때문입니다. 즉, context 길이가 길어질수록 처리 비용이 엄청나게 빠르게 증가한다는 뜻이죠. Linear Transformer는 이 속도 문제를 해결하기 위해 발명되었지만, 정보를 작은, 고정 크기 메모리에 너무 많이 압축하기 때문에 정확도가 떨어지는 경우가 많습니다. 마치 전체 책을 몇 개의 요점으로 요약하는 것과 같아요. 많은 세부 정보가 사라지죠!
새로운 점 & 기여: Titans와 Neural Long-Term Memory의 등장! 이 논문의 핵심 아이디어는 AI 모델에게 attention의 단기 기억과는 별개의, 학습 가능한 long-term memory 모듈을 제공하는 겁니다. 마치 현재 문장에 집중하는 작업 기억 (attention)과 전체 책에서 얻은 지식 (long-term memory)을 함께 사용하는 것과 같죠.
핵심적인 새로운 점: Titans는 테스트 시간에 기억하는 법을 학습하는 neural long-term memory를 도입합니다. 이건 단순히 데이터를 저장하는 게 아니라, AI가 정보를 처리하면서 효과적으로 기억하는 방법을 능동적으로 학습하는 거죠. 인간의 기억에서 영감을 얻어 "surprise" 메트릭을 사용하여 무엇을 기억할지 결정합니다. 이건 meta-learning 접근 방식입니다. 메모리 모듈이 학습하고 기억하는 방법을 학습하는 거죠. 게다가, 이들은 이 long-term memory를 Titans라고 부르는 아키텍처에서 전통적인 attention (short-term memory)과 통합하는 다양한 방법을 설계하여 유연성과 효율성을 제공합니다. 이것은 단순히 attention을 더 빠르게 만드는 것에서 벗어나, AI 모델이 메모리를 처리하는 방식을 근본적으로 다시 생각하는 중대한 변화입니다. 인간의 인지에서 영감을 얻은 거죠! 한마디로: "Attention은 현재에 집중하는 데는 좋지만, 과거를 위해서는 다른 종류의 메모리가 필요하고, AI는 그걸 효과적으로 사용하는 법을 학습할 수 있다!"라고 말하는 겁니다.
Method:
자, 이제 Titans가 실제로 어떻게 기억하는 법을 배우는지 자세히 알아봅시다. 좀 복잡하게 들릴 수도 있지만, 차근차근 살펴볼게요.
1. Neural Long-Term Memory: Surprise로부터 배우기
Titans의 핵심은 neural long-term memory module입니다. 이 모듈은 과거의 정보를 저장하고 검색하는 방법을 배우는 별도의 neural network와 같습니다. 그런데 무엇을 기억할지는 어떻게 결정할까요? 핵심 아이디어는 바로 surprise입니다!
생각해보세요. 놀랍거나 예상치 못한 일을 더 잘 기억하는 경향이 있잖아요? Titans의 메모리 모듈도 비슷하게 작동합니다. surprise metric을 사용해서 각각의 새로운 정보가 얼마나 "예상 밖"인지 파악하는 거죠.
이 surprise metric은 neural network의 입력에 대한 gradient를 사용하여 계산됩니다. "gradient"라는 기술 용어에 너무 얽매이지 마세요. 그냥 모델의 "기대"가 새로운 입력에 의해 얼마나 위반되는지를 측정하는 거라고 생각하면 됩니다. 큰 gradient는 높은 surprise를 의미합니다. 즉, 모델이 새롭거나 예상치 못한 것을 배우고 있다는 거죠.
메모리 업데이트 방정식 (초기 Surprise Metric):
$$M_t = M_{t-1} - \theta_t \nabla l(M_{t-1}; x_t)$$
하나씩 뜯어볼까요:
- $M_t$: 현재 시점 $t$에서의 메모리입니다. 장기 기억의 현재 상태라고 생각하면 됩니다.
- $M_{t-1}$: 이전 시점의 메모리입니다. 지금까지 쌓아온 메모리죠.
- $x_t$: 현재 시점의 새로운 입력입니다.
- $\nabla l(M_{t-1}; x_t)$: 이게 바로 surprise metric입니다. loss function $l$ (모델이 얼마나 잘 수행하고 있는지를 측정)의 메모리 $M_{t-1}$과 입력 $x_t$에 대한 gradient입니다. gradient가 클수록 surprise가 크다는 뜻이죠.
- $\theta_t$: surprise에 따라 메모리가 얼마나 업데이트되는지를 제어하는 learning rate입니다.
쉽게 말하면: 메모리 $M_t$는 이전 메모리 $M_{t-1}$을 가져와서 surprise ($\nabla l(M_{t-1}; x_t)$)에 따라 조정하는 방식으로 업데이트됩니다. surprise가 클수록, 이 새롭고 예상치 못한 정보를 통합하기 위해 메모리가 더 많이 변합니다.
개념 체크포인트: 지금까지, 새로운 정보가 얼마나 놀라운지에 따라 업데이트되는 메모리 모듈을 살펴봤습니다. 이건 마치 장기 기억을 돋보이고 기대에 어긋나는 일에 집중시키는 것과 같죠.
2. Surprise Metric 개선: Past and Momentary Surprise
초기 surprise metric도 좋지만, 더 개선할 수 있습니다. 때로는 중요한 정보가 큰 surprise 이후에 나타날 수 있는데, surprise metric이 너무 빨리 작아지면 모델이 놓칠 수 있습니다. 이걸 해결하기 위해, Titans는 surprise metric을 두 부분으로 나누어 개선합니다.
- Past Surprise ($S_{t-1}$): 최근 과거의 surprise를 측정합니다. 최근에 놀라운 일이 있었는지를 추적하는 것과 같습니다.
- Momentary Surprise ($\nabla l(M_{t-1}; x_t)$): 현재 입력으로부터의 surprise입니다. 초기 metric과 동일하죠.
개선된 메모리 업데이트 방정식:
$$M_t = M_{t-1} + S_t$$
$$S_t = \eta_t S_{t-1} - \theta_t \nabla l(M_{t-1}; x_t)$$
자세히 살펴보죠:
- $M_t$와 $M_{t-1}$는 이전과 마찬가지로 현재 및 이전 시점의 메모리입니다.
- $S_t$: 시점 $t$에서의 total surprise입니다. 과거와 현재 surprise의 조합이죠.
- $S_{t-1}$: 이전 시점의 past surprise입니다.
- $\eta_t$: data-dependent surprise decay입니다. 과거 surprise ($S_{t-1}$)가 현재로 얼마나 많이 전달되는지를 제어합니다. $\eta_t$가 1에 가까우면 과거 surprise가 강한 영향을 미칩니다. 0에 가까우면 과거 surprise는 빠르게 잊혀지죠. 이건 context 변화를 처리하는 데 중요합니다.
- $\theta_t$: 여전히 learning rate이며, momentary surprise가 업데이트에 얼마나 영향을 미치는지 제어합니다.
- $\nabla l(M_{t-1}; x_t)$: 이전과 동일한 momentary surprise입니다.
쉽게 말하면: 메모리 $M_t$는 total surprise $S_t$를 더하여 업데이트됩니다. total surprise $S_t$는 past surprise*의 감쇠된 버전 ($ηt S{t-1}$)을 취하고 *momentary surprise ($\theta_t \nabla l(M_{t-1}; x_t)$)를 빼서 계산됩니다. $S_t$를 surprise의 "모멘텀"이라고 생각하면 됩니다. 과거 surprise를 축적하지만, 현재 surprise에 의해서도 구동되죠.
Gradient Descent with Momentum과의 유사성: 흥미롭게도, 저자들은 이 공식이 neural network에서 일반적인 최적화 기술인 gradient descent with momentum과 유사하다고 지적합니다. $S_t$는 모멘텀처럼 작용하여 "surprise" 신호를 시간 경과에 따라 전달합니다.
개념 체크포인트: 이제 과거와 현재 surprise를 모두 고려하는 더 정교한 surprise metric을 갖게 되었습니다. surprise decay ($\eta_t$)는 모델이 데이터 context에 따라 기억하는 방식을 조정할 수 있게 해줍니다. 이건 즉각적인 surprise에 반응할 뿐만 아니라 시간 경과에 따른 surprise 패턴에도 민감한 메모리를 갖는 것과 같죠.
3. Forgetting Mechanism: Adaptive Memory Management
매우 긴 시퀀스를 다룰 때, 단순히 메모리를 축적하기만 하면 "memory overflow"가 발생하고 성능이 저하될 수 있습니다. Titans는 메모리 용량을 관리하기 위해 forgetting mechanism을 도입합니다. 이 메커니즘은 과거 메모리를 얼마나 잊을지 적응적으로 결정합니다.
Forgetting Mechanism을 포함한 방정식:
$$M_t = (1 - \alpha_t) M_{t-1} + S_t$$
- $M_t$, $M_{t-1}$, $S_t$는 이전과 동일합니다.
- $\alpha_t$: data-dependent forgetting gate이며, 0과 1 사이의 값입니다. 이전 메모리 $M_{t-1}$을 얼마나 유지할지 제어합니다. $\alpha_t$가 0에 가까우면 이전 메모리의 대부분이 유지됩니다. 1에 가까우면 이전 메모리의 대부분이 잊혀지죠.
쉽게 말하면: 메모리 $M_t$는 이전 메모리 $M_{t-1}$의 일부분 $(1 - \alpha_t)$을 가져와서 total surprise $S_t$를 더하여 업데이트됩니다. forgetting gate $\alpha_t$는 현재 입력을 기반으로 과거 메모리를 얼마나 "decay"하거나 잊을지 학습합니다.
Weight Decay와의 유사성: 저자들은 또한 이 forgetting mechanism이 overfitting을 방지하는 데 도움이 되는 neural network의 regularization 기술인 weight decay와 관련이 있다고 언급합니다. 여기서는 memory overflow를 방지하고 관련 정보에 집중하는 데 사용됩니다.
개념 체크포인트: forgetting mechanism을 통해 Titans의 메모리는 적응적이고 효율적이 됩니다. 인간의 기억처럼 중요한 정보는 기억하고 덜 중요한 세부 사항은 잊는 법을 배울 수 있죠!
4. Titans 아키텍처: Long-Term Memory 통합

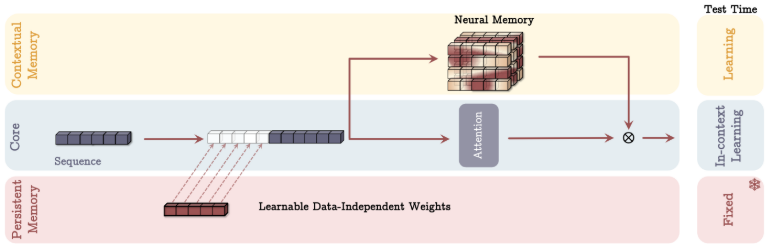
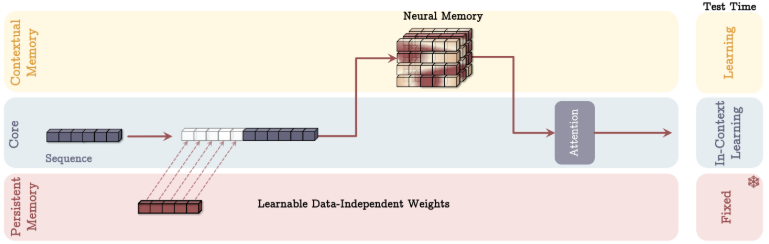
이제 neural long-term memory module이 있으니, 이걸 실제로 neural network 아키텍처에서 어떻게 사용할까요? 이 논문에서는 이 메모리를 Titans라고 부르는 아키텍처에 통합하는 세 가지 주요 방법을 제안합니다.
- Memory as a Context (MAC): 이 아키텍처에서는 long-term memory의 출력이 attention에 의해 처리되기 전에 현재 입력과 결합되는 추가 "context"로 취급됩니다. attention이 short-term (현재 입력) 및 long-term memory context 모두에 접근할 수 있도록 하는 것과 같죠.
- Memory as a Gate (MAG): 여기서 long-term memory는 핵심 처리 분기 (attention과 같은 short-term memory를 사용)의 정보가 persistent memory와 결합되는 방식을 제어하는 "gate" 역할을 합니다. long-term memory를 사용하여 정보 흐름을 필터링하거나 조절하는 것과 같죠.
- Memory as a Layer (MAL): 이 경우, long-term memory module 자체가 neural network의 layer 역할을 하여 attention 메커니즘을 통과하기 전에 입력 시퀀스를 처리합니다. attention이 현재 context에 집중하기 전에 전용 메모리 처리 단계를 갖는 것과 같죠.
또한, LMM (Long-term Memory Module)을 attention이 없는 독립형 모델로 평가하여 long-term memory 자체가 얼마나 효과적인지 확인합니다.
개념 체크포인트: Titans는 short-term (attention) 및 long-term memory를 결합하는 다양한 방법을 제공하여 네트워크 내에서 메모리가 활용되는 방식에 유연성을 제공합니다.
5. 효율성을 위한 병렬화:

이러한 long-term memory module을 효율적으로 훈련하는 것은 매우 중요합니다. 이 논문에서는 mini-batch gradient descent와 matmul operations를 사용하여 훈련 프로세스를 병렬화하는 영리한 방법을 설명합니다. 시퀀스를 청크로 나누고 메모리 업데이트 규칙을 GPU 및 TPU에서 고도로 최적화된 행렬 곱셈 (matmuls)을 사용하여 효율적으로 계산할 수 있도록 재구성합니다. 이렇게 하면 특히 긴 시퀀스의 경우 Titans 훈련 속도가 훨씬 빨라집니다.
전체 방법 요약: Titans는 surprise를 기반으로 기억하는 법을 배우고, 과거 surprise를 통합하고, 적응적으로 잊고, 다양한 아키텍처에 통합될 수 있는 neural long-term memory module을 도입합니다. 훈련 프로세스도 효율성을 위해 병렬화됩니다. AI 모델에 효과적인 long-term memory를 장착하기 위한 포괄적인 접근 방식이죠!
실험 결과:
Titans가 실제로 작동하는지 확인하기 위해 연구자들은 다양한 까다로운 task에 대한 광범위한 실험을 수행했습니다.
- Language Modeling and Common Sense Reasoning: 표준 언어 벤치마크와 상식 추론 task에서 Titans를 테스트했습니다. 결과: Titans, 특히 MAC, MAG, MAL 변형은 최첨단 linear recurrent 모델과 context window가 제한된 Transformer보다 우수한 성능을 보였습니다. 독립형 LMM도 강력한 성능을 보여 long-term memory module 자체의 강력함을 강조했습니다.
- Needle-in-a-Haystack (NIAH) Task: 이건 long-context 이해를 테스트하기 위해 특별히 설계된 task입니다. 모델은 매우 긴 문서 ("haystack") 안에 숨겨진 특정 정보 ("needle")를 찾아야 합니다. 결과: Titans (특히 MAC)는 GPT-4와 같은 매우 큰 모델을 포함한 모든 baseline보다 훨씬 뛰어난 성능을 보였습니다. 이는 Titans가 극도로 긴 context를 처리하고 먼 과거로부터 정보를 검색하는 능력이 탁월함을 입증했습니다. haystack이 길어져도 Titans의 성능은 다른 모델만큼 저하되지 않아 더 나은 확장성을 보여주었습니다.
- BABILong Benchmark: 매우 긴 문서에 분산된 사실들을 추론해야 하는 훨씬 더 어려운 long-context 추론 task입니다. 결과: 다시 한번, Titans (MAC)는 GPT-4와 같은 매우 큰 모델과 심지어 다른 모델의 fine-tuned 버전을 포함한 모든 baseline보다 뛰어난 성능을 보였습니다. 이는 Titans가 복잡한 long-context 시나리오에서 효과적임을 더욱 입증했습니다.
- Time Series Forecasting: Titans는 시계열 데이터의 미래 값을 예측하는 데 테스트되었습니다. 결과: neural memory module (LMM)은 specialized time series 모델을 포함한 모든 baseline보다 뛰어난 성능을 보여 언어뿐만 아니라 다양한 분야에 적용될 수 있음을 보여주었습니다.
- DNA Modeling: Titans는 DNA 모델링 task에서도 평가되어 과학 데이터에 대한 적용 가능성을 보여주었습니다. 결과: LMM은 genomics 분야의 최첨단 아키텍처와 경쟁할 만한 성능을 보여 광범위한 적용 가능성을 보여주었습니다.
- Ablation Studies: Titans의 각 구성 요소의 기여도를 이해하기 위해 convolution, momentum, weight decay, persistent memory와 같은 부분을 제거하는 ablation studies를 수행했습니다. 결과: 모든 구성 요소가 성능에 긍정적인 영향을 미쳤으며, weight decay, momentum, convolution, persistent memory가 가장 큰 영향을 미쳤습니다.
- Memory Depth Analysis: neural memory module의 다양한 깊이를 테스트했습니다. 결과: 더 깊은 메모리 (더 많은 layer)는 일반적으로 특히 더 긴 시퀀스에서 더 나은 성능으로 이어졌지만, 훈련 속도는 약간 느려졌습니다. 이는 메모리 깊이, 성능, 효율성 간의 trade-off를 보여주었습니다.
전반적인 실험 검증: 실험 결과는 neural long-term memory module을 갖춘 Titans가 기존 모델보다 특히 long-context 이해가 필요한 task에서 훨씬 더 효과적임을 설득력 있게 보여줍니다. 또한 효율적이고 확장 가능하여 방대한 양의 정보를 처리하고 기억해야 하는 미래 AI 시스템에 유망한 접근 방식입니다.
리뷰:
이 논문은 AI 메모리 분야에서 정말 흥미로운 발전을 제시합니다! 학습 가능한 neural long-term memory를 갖춘 "Titans" 아키텍처는 AI 모델이 긴 context를 처리하고 시간이 지나도 정보를 "기억"할 수 있는 강력하고 효율적인 방법을 제공합니다. 핵심 혁신은 "surprise" 기반 학습 메커니즘으로, 메모리 모듈이 인간의 인지에서 영감을 받아 무엇을 기억하고 언제 잊을지 적응적으로 학습할 수 있도록 합니다. 실험 결과는 인상적이며, Titans는 특히 long-context 시나리오에서 다양한 까다로운 task에서 최첨단 모델을 능가하는 성능을 보여줍니다. 이 연구는 방대한 양의 데이터로부터 효과적으로 추론하고 학습할 수 있는 AI 시스템을 구축할 수 있는 새로운 가능성을 열어줍니다. 마치 인간처럼요. AI 모델이 고정 크기 메모리에 의존하는 대신 테스트 시간에 어떻게 기억하는지 능동적으로 학습한다는 아이디어는 중대한 진전이며 AI의 미래에 큰 영향을 미칠 수 있습니다!