시작하며
저번 포스팅에서는 비지도학습(Unsupervised Learning)의 기초 개념을 다뤄보았습니다. 이번 포스팅에서는 Unsupervised Learning의 원리를 알아보고 이것의 대표적인 알고리즘인 'K-means algorithm'에 대해 다뤄보겠습니다.
이번 포스팅은 아래 포스팅을 보시고 공부하시면 더욱 효과적입니다.
비지도 학습(Unsupervised Learning)이란? : Clustering
시작하며 우리가 그동안 이전 포스팅에서 배웠던 Linear Regression, Logistic Regression, Neural Network, SVM은 모두 지도학습(Supervised Learning) 즉 레이블(Label)이 있는 데이터에 대한 학습이었습니다...
box-world.tistory.com
Unsupervised Learning의 작동 원리
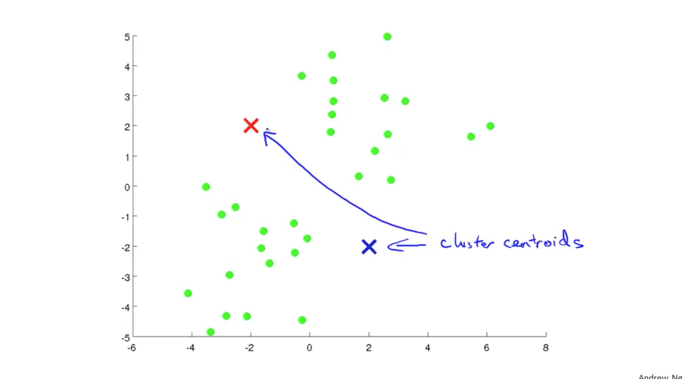
** Cluster란 하나의 **군집화된 데이터 그룹을 의미합니다. 우선 위와 같은 데이터를 두 개의 Cluster로 나눠보겠습니다.
이때 Cluster의 갯수가 정해지면 동일한 갯수의 Cluster Centroids(중심점)가 동시에 랜덤으로 지정됩니다. 이는 각 Cluster의 일종의 대표 역할을 하게 됩니다. 이렇게 Cluster의 갯수만큼 Centroids를 생성하여 위치시키는 것이 Unsupervised Learning의 첫번째 단계가 됩니다.

이제 두번째 단계로 위치시킨 두개의 Cluster Centroids을 기준으로 나머지 데이터들을 두 개의 Cluster 중 하나로 구분합니다.
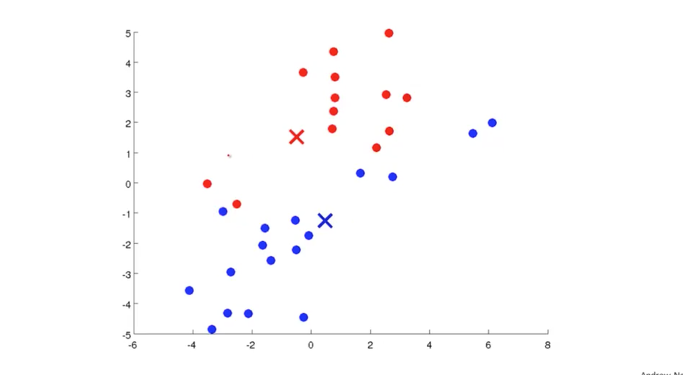
다시 첫번째 돌아와서 Cluster Centroid의 위치를 조정하게 되는데, 이때는 나름의 기준을 가지고 조정하게 됩니다. 그 다음 마찬가지로 나머지 데이터들도 다시 새롭게 구분됩니다.

첫번째로 Cluster Centroid를 설정하여 데이터를 나누고, 두번째로 Cluster Centroid를 조정하는 단계를 반복적으로 거치면서 점점 데이터들을 적절하게 구분이 되어갑니다. 이를 통해 학습 모델이 형성되고 적절하게 Cluster된 결과를 얻을 수 있습니다.
K-means Algorithm

K-means Algorithm은 위에서 봤던 내용과 비교했을 때, 기본적인 작동 원리는 동일하며, 어떻게 매 단계마다 Cluster Centroids를 갱신하는지 주목하면 좋습니다. 알고리즘은 두개의 입력값을 가집니다. 하나(K)는 데이터를 몇 개의 Cluster로 구분할 것인가, 다른 하나는 구분할 dataset입니다.
K-means Algorithm은 Unsupervised Learning을 다루므로 데이터의 Label을 존재하지 않습니다. 따라서 dataset은 $(x_1,y_1), (x_2, y_2)... $의 형태가 아닌 $x_1, x_2...$의 형태가 됩니다. 이어서 data가 n개라면 $x_0$를 포함하여 dataset은 $n+1$차원의 vector로 표현 가능합니다.

만약 데이터를 k개의 Cluster로 분류하게 되면, 마찬가지로 주어진 데이터 중 k개의 Clsuter Centroid를 랜덤으로 지정하게 되고 이것들은 $μ_k$로 표기합니다. 작동원리는 다음과 같습니다.
1) Cluster assignment : 초기에 랜덤으로 지정된 k개의 Cluster Centroids를 기준으로 나머지 데이터들이 어느 $μ_k$에 가까운지 체크하여 구분하게 되며 이 결과를 $c(i)$로 표기합니다. 예를 들어 $c(24) = 2$라면 24번째 데이터가 2번째 Cluster로 구분된 것입니다.
2) Move centroid : 이 단계에서는 K개의 Cluster Centroids를 새로운 위치로 갱신하게 됩니다. 구체적으로 $μ_k$는 k번째 Cluster는 k 번째 Cluster에 포함된 데이터의 평균 값을 구하여 그 위치로 이동하게 됩니다. 예를 들어 $x(1), x(5), x(6), x(7)$이 2번째 Cluster에 포함된다면, $c(1), c(5), c(6), c(7)$은 모두 2일 것이며 $μ_2$는 이 이들의 평균값인 $\frac{1}{4}(x(1) + x(5) + x(6) + x(7)$의 위치로 갱신됩니다.
알고리즘은 단계를 반복하면서, 반복해도 결과가 바뀌지 않거나(수렴), 사용자가 지정한 roop를 수행하게 되면 종료됩니다.
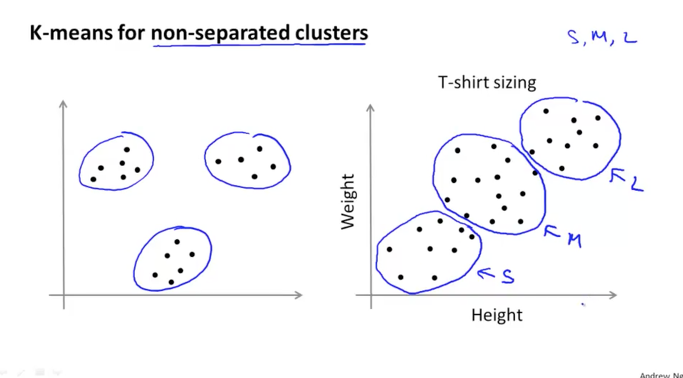
육안으로 보기에 분리가 쉽게 되는 경우도 있지만, 오른쪽 그래프처럼 불규칙하여 쉽게 분리할 수 없을거 같이 보이는 그래프도 Clustering이 가능합니다. 오른쪽 그래프는 T-shirt의 Size를 small, medium, large 3개의 cluster로 구분한 결과입니다.

이제 K-means Algorithm의 특징과 단점에 대해 알아보겠습니다. 우선 첫 단계에서 Cluster Centroids를 랜덤으로 설정하게 되는데 이 초기 랜덤값인 Cluster Centroids에 따라 결과값이 달라질 수 있습니다.

또한 군집의 밀도가 서로 다를 때 작동하지 않을 수 있습니다.