시작하며
저번 포스팅에서는 SVM의 Margin에 대해 다루며, 선형으로 분리되는 데이터의 Decision Boundary를 어떻게 지정할 것인가에 대해 다뤄보았습니다. 하지만 이 세상의 대부분의 데이터는 대부분 선형으로 분류되지 않습니다. 결국 우리가 주목해야할 부분은 선형 분류가 아니라 비선형 분류라는 점입니다.
이번 포스팅에서는 비선형으로 분류되는 데이터의 Decision Boundary를 지정하기 위해 이용되는 SVM의 Kernal에 대해 알아보겠습니다.
이번 포스팅은 아래 포스팅을 공부하시고 보시면 더욱 효과적입니다.
https://box-world.tistory.com/25
https://box-world.tistory.com/26
SVM Preview
우선은 Kernal이라는 개념이 어떻게 나오게 되었는지 SVM을 잠시 복습하면서 알아보겠습니다.

SVM Introduction의 후반부에서 잠깐 언급했던 Hard Margin과 Soft Margin이 기억나시나요?
보통 데이터를 분류하려 할 때 데이터 그룹과 동떨어져 있는 Outlier까지 철저하게 분류하는 것을 Hard Margin, Outlier를 어느정도 눈감으면서 최대의 Margin을 가지는 Decision Boundary를 지정하고자 했던 것이 Soft Margin이었습니다.
사실 이 Soft Margin은 비선형 분류를 다루기 위해 Kernal이 나오기전 사용하던 방법이었습니다. 그러나 outlier를 어느정도 무시하고 Decision Boundary를 정한다는 점에서 분명한 한계가 있었고, 이에 따라 나오게 된게 바로 Kernal입니다.
What is Kernal in SVM
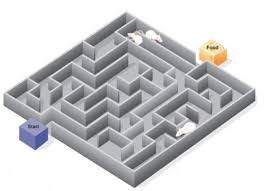
여기 미로가 하나 있고, 우리는 시작점에 쥐를 놓고 출구에 도착하는지 지켜볼 것입니다. 쥐 입장에서는 미로가 어떻게 생겼는지 알 수 없기 때문에 이곳저곳을 돌아다니면서 출구를 찾을 것입니다. 하지만 그걸 지켜보는 우리 입장에서는 위에서 미로의 구조를 내려다보고 있기 때문에 어떻게 가야 출구를 찾을 수 있을지를 단번에 알 수 있습니다.

이것이 바로 비선형 데이터를 분류하는 핵심 아이디어입니다. 2차원에서는 non-linear한 형태로 복잡하게 분류해야 하던 데이터를 3차원으로 확장하면, 초평면 형태의 Decision Boundary로 쉽게 분류할 수 있습니다.
하지만 여기에는 한가지 문제점이 있습니다. 우리는 저번 포스팅에서 최적의 Decision Boundary를 찾기 위해서 Vector의 내적을 이용했었는데, 모든 데이터를 3차원으로 확장하여 vector의 내적을 구하기엔 연산 비용이 많이 든다는 것입니다. 따라서 나오게 된 것이 바로 Kernal 트릭입니다.
Kernal 트릭의 기본 아이디어는 데이터를 2차원에서 3차원으로 맵핑하지 않고, Decision boundary를 구하는데 필요한 맵핑된 데이터의 내적값 바로 뽑아내자는 것입니다. 이제 구체적으로 이것이 어떤 의미인지 살펴보겠습니다.

우선 용어 몇가지를 짚고 가겠습니다. 데이터를 n차원에서 n+1차원으로 옮기는 것을 맵핑(mapping)이라고 표현합니다. 이때 기존에 Input이 들어있던 곳을 Input space, 차원이 확장된 맵핑 데이터가 들어있는 곳을 Feature Space라고 합니다.
2차원 데이터 x를 3차원으로 맵핑한 데이터를 l(x)(=라고 하겠습니다. Kernal이란 연속함수 K(x,y)로 실수, 함수, 벡터등을 인자로 받고 실수값을 내뱉는 symmetric한 함수입니다.(K(x,y) = K(y,x))
즉 SVM에서 Kernal을 이용한다는 건 삼차원에서 맵핑된 l(x)와 이차원에서의 x를 인자로 받고 내적값을 내뱉기 때문에 굳이 수고롭게 데이터를 하나하나 3차원에 맵핑할 필요가 없는 것입니다.
근데 여기서 우리는 한가지 의문점이 듭니다.
"음... 내 눈으로 직접 2차원에서 3차원으로 맵핑된 데이터를 보지 않고, kernal을 이용하여 내적 값을 바로 뽑아낼 수 있는건 알겠는데, Kernal을 이용하다가 실수로 3차원에서 존재하지도 않던 데이터의 내적값을 반영하게 되진 않을까요?"
다행인것은 mercer theorem 덕분에 Kernal이 mercer theorem을 만족하기만 한다면, 우리가 사용할 커널에 이용되는 맵핑 값은 무조건 삼차원에서 존재할 것이라고 생각하면 됩니다.
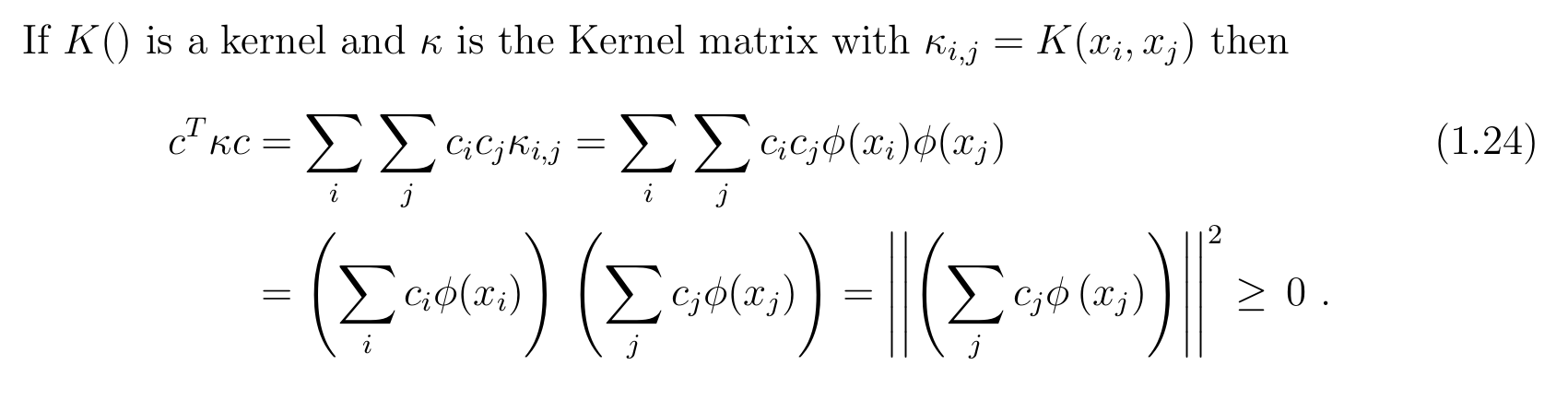
mercer theorm은 위와 같은데, 수학적으로 깊이 다루지는 않겠습니다. 다만 우리가 주목해야할 점은 이 theorm을 만족하는 커널 함수에는 네가지 종류가 있고, theorm을 만족하는 네가지 함수를 이용하면, Input으로 들어온 비선형 분류 데이터 x가 몇차원이 되었건, 이것을 무한대 차원의 Feature space로 확장시킬 수 있다는 점입니다. 우리는 이중 성능이 가장 좋은 Gausiian Kernal을 사용할 것입니다.
Gaussian Kernal
여기 세 개의 data에 대해 맵핑된 세개의 l(x)가 있습니다. 그리고 여기 세개의 f가 있습니다. 이것이 바로 Kernal 함수인데, 인자로 $x_i$와 $l_i$를 받습니다. 이것은 $x_i$와 $l_i$이 얼마나 유사성이 큰지(근접한지) 측정하는 방법이 됩니다.
인자 값의 변화에 따라 kernal 값의 어떤 변화가 있는지 알아보겠습니다. 만약 x와 l이 비슷하다면 분자가 0이 되어 함수는 1에 가까운 값이 됩니다. 반대로 x와 l이 멀수록 분자값이 커져서 함수값은 0에 가까워집니다.

예를 들면, 위와같이 l^{(1)}이 [3,5]의 값을 가지고 있습니다. 이때, $σ^2 = 1$이라 할때, x값이 [3,5]에 가까울 수록 f의 값은 1이 되고 멀어질수록 0의 값을 갖게 됩니다.
이때 $σ^2$은 분산으로 이것이 크면 클수록 그래프의 모양이 날카롭게 변하고, 작으면 작아질수록 그래프의 모양이 퍼지게 됩니다. 이를 다시 해석하면 $σ^2$값에 따라 x값이 미치는 영향의 범위가 작아지거나 커진다고 할 수 있습니다.

여기 세타와 f로 표현된 함수가 있습니다. 이 함수 값이 0 이상일 때 1이라고 예측합니다. $θ_0~θ_3$이 각각 [-.5, 1, 1, 0]의 값을 가진다 할 때, $l_1$ 근처의 x 값을 살펴보겠습니다. 이 경우 $f_1 ~ f_3$은 [1, 0, 0]의 값을 가지면서 결과값은 0.5가 되고 이것은 0 이상이니 최종 예측값은 y = 1이 됩니다. 실제로 x값이 $l_1$과 근접하니 1이 나오는것은 당연한 결과입니다.
이번엔 좀 동떨어져 있는 $x^'$이 있습니다. 이 경우 $f_1 ~ f_3$은 [0, 0, 0]의 값을 가지면서 결과값은 -0.5가 나오고 최종 예측값은 y = 0이 됩니다. 이것 또한 x 값이 $l_1$과 멀리 떨어져 있으니 당연한 결과입니다. 이렇게 하여 생성되는 Decision Boundary는 빨간색과 같습니다.

이번엔 앞에서 3개의 data를 가지는 경우를 data가 m개인 경우로 확장해보겠습니다. 이 경우 m개의 $x^{(i)}$에 대해 똑같이 m개의 $l^{(i)}$가 생성되고, m개의 $f^{(i)}$를 이용하여 각 $x^{(i)}$와 $l^{(i)}$가 얼마나 유사한지 측정하게 됩니다.

이제 위에서 배운 것을 우리가 기존에 알던 SVM의 cost함수에 적용해보겠습니다. 이 경우 우리는 x 대신 m+1개의 $f^{(i)}$가 들어갑니다. 이때 $f^{(i)}$가 m개가 아닌 m+1개인 이유는 일종의 bias term으로 1의 값을 갖는 $f^0$이 포함되어있기 때문입니다. 그리고 $θ$가 m 사이즈만큼 있으므로 맨 뒤 $Σθ^2$에서 n = m이 될것입니다. 이때 $θ^2$는 $θ^Tθ$로 표현가능한데 이것은 ${||θ||}^2$이기 때문에 다시 $θ^TMθ$로 표현될 수 있습니다. 이때 $M$은 Kernal에 대한 Matrix로 $θ$를rescale하는 역할을 하며 연산의 효율성을 높여줍니다.
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [머신러닝 순한맛] 비지도 학습(Unsupervised Learning)이란? : Clustering (0) | 2020.05.15 |
|---|---|
| [머신러닝 순한맛] SVM(Support Vector Machine)이란? - 4) Preview (1) | 2020.05.12 |
| [머신러닝 순한맛] SVM(Support Vector Machine)이란? - 2) Margin (3) | 2020.05.06 |
| [머신러닝 순한맛] SVM(Support Vector Machine)이란? - 1) Introduction (0) | 2020.05.05 |
| [머신러닝] 머신러닝 시스템 디자인 하기 : Precision, Recall, F score (3) | 2020.05.04 |