시작하며
우리가 데이터를 모델에 학습시킬 때, 모델이 학습한 결과와 실제값이 달라 accuracy(정확도) 가 떨어지는 상황에서 무엇을 할 수 있을까요?
-
더 많은 데이터를 넣어본다? 데이터의 표본이 많아지면 학습을 더 많이 하니까 정확해질거라 생각하지만 시간만 오래 걸리고 생각보다 도움이 되지 않습니다.
-
feature를 줄여보자? OverFitting을 방지하기 위해 feature를 줄여보는 시도를 해볼 수 있습니다.
-
반대로 feature를 더 늘려보자? 학습 시 dataset의 feature가 부족하여 정확한 결과가 나오지 않을 수도 있습니다.
-
가설함수를 복잡하게 해보자? 가설함수가 너무 단순해서 정확도가 떨어졌을거란 생각에 복잡하게 바꿔볼 수도 있습니다.
-
Regularzation 시 람다값을 조정해보자? 정규화가 제대로 되지 않았다고 생각하여 람다값을 조정해볼 수 있습니다.
하지만 아무것도 모르고 감으로 이것들을 했다간 되려 시간을 낭비할 수 있습니다.
이번 포스팅에서는 모델 학습 시 높은 accuracy를 위해 필수적인 Test Data 와 Cross Validation data 에 대해서 공부해보겠습니다.
이번 포스팅은 아래 포스팅을 먼저 공부하시고 보시면 더욱 효과적입니다.
- [쉬운 머신러닝] 모델의 과적합(Overfitting)을 피하기 위한 방법
https://coffeeguy827.github.io/deeplearning/OverFitting/
Test Data
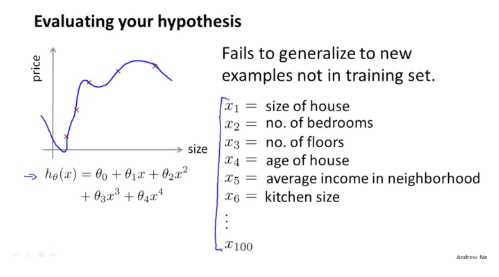
우리에게 데이터가 100개인 dataset이 주어졌습니다. 그런데 우리가 기존에 하던대로 이 데이터 100개를 모조리 모델 학습에 사용하게 되면, 가설함수 h는 Overfitting되어 accuracy가 떨어지게 됩니다.
그래서 핵심은 이 데이터 100개를 모조리 모델 학습에 사용하는 것이 아니라 몇 개의 그룹으로 나누어 목적에 맞게 각각 다르게 사용하자라는 것입니다.

첫번째는 'Test Data' 입니다. Test Data는 보통 전체 데이터의 30% 로 책정하며, 모델의 성능을 측정하는데 사용합니다.
쉽게 말해서 우리에게 100개의 data가 주어진다면 이것을 모두 학습에 사용하는게 아니라, 30%를 떼어놓고 70%만 학습에 사용한 후 모델의 성능을 측정하는데 나머지 30%를 사용하는 것입니다.
이때 나누기전 data가 정렬되어 있다면, Mix하고 나눠줘야 합니다.

예를 들어 'Logistic Regression'의 경우에, Data set을 7:3으로 나눕니다. 즉 70%으로 Cost 함수의 비용을 최소화하는데 사용하고, 나머지 30%의 데이터를 학습시킨 모델에 넣어보고 오차를 비교해봅니다.
이때 오차는 test data의 실제값은 true인데 모델이 예측한 값은 false일 때 발생할 것입니다.
Cross Validation data for Model Selection

Overfitting만 보더라도 training dataset에 잘 맞는다고 좋은 가설함수라고 단정짓기 어렵습니다. 따라서 우리는 모델 학습을 위한 데이터, 모델 성능 평가를 위한 데이터 이외에 모델을 결정하기 위한 데이터가 별도로 필요합니다.
CV data는 한마디로 가설함수 h(학습 모델)를 결정하기 위해 Test data처럼 따로 떼어놓는 데이터입니다. 위처럼 OverFitting 혹은 Underfitting한 가설함수를 만들지 않기 위해 필요한 데이터인 것입니다.
여기 1차부터 10차 방정식까지 10가지의 가설함수 중 하나를 골라야 하는 상황이 있습니다.
그런데 Cv data없이 각각 test data로 학습한 후 Cost를 서로 비교해서 Cost가 가장 작은 가설함수를 고르면 안되는 걸까요?

만약 저렇게 하게 되면 test data는 가설함수를 결정하는데 한번, 학습이 끝난 후 성능을 평가하는데 총 두번 사용됩니다.
문제는 모델을 결정할 때 test data를 사용하면서, 모델 결정 후 성능을 평가할 때 모델이 미리 test data를 학습한 탓에 상대적으로 적은 Error가 나오게 된다는 것입니다.
즉 제대로 된 성능 평가를 할 수 없게 되는 것입니다. 이러한 이유로 우린 주어진 dataset을 Training data, Test data, Cv data 총 세가지로 나누어 사용해야 하는 것입니다.

그래서 일반적으로 dataset을 Training set : CV set : Test set의 비율을 60 : 20 : 20로 나누어 학습에 이용하고 세 가지의 dataset의 Cost 공식은 위와 같습니다.

요약
1) Training data : 모델 학습 을 위한 데이터
2) Test Data : 학습한 모델의 성능 평가 를 위한 데이터의
3) CV data : 학습시킬 모델을 결정 하기 위한 데이터
4) 일반적으로 Training set : CV set : Test set = 60 : 20 : 20
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [머신러닝] 머신러닝 시스템 디자인 하기 : Precision, Recall, F score (3) | 2020.05.04 |
|---|---|
| [머신러닝] 머신러닝 학습 시 고려해야 하는 것 : High Bias vs High Variance, Learning Curve (0) | 2020.05.03 |
| [머신러닝] 딥러닝의 시작 Neural Network 정복하기 2 (0) | 2020.05.01 |
| [머신러닝] Back Propagation(역전파) 정복하기 (2) | 2020.05.01 |
| [머신러닝] Neural Network를 이용한 XNOR 연산 그리고 Multi Classification (0) | 2020.05.01 |