시작하며
머신러닝 시스템을 디자인하면서 적용해볼 수 있는 방법들은 다양하게 존재합니다.
이번 포스팅에서는 여러 방법들 중에 하나의 최선의 방법을 골라 적용할지 판단하는 체계적인 방식을 배워보도록 하겠습니다.

우리는 이제부터 스팸 메일을 분류하는 시스템을 만들고자 합니다.
우리가 생각할 수 있는 첫번째 방법은 이메일의 feature를 x, 이메일이 스팸 여부를 y로 놓겠습니다(스팸 = 1, 정상 = 0) 이메일의 feature는 스팸인지 아닌지 판별할 수 있는 100개의 단어를 선택하여 각 단어가 이메일 속에 들어있는지 비교하여 들어있으면 1, 그렇지 않으면 0으로 처리할 것입니다.
따라서 이메일의 feature x는 단어 포함 여부를 나타내는 100차원의 vector가 될 것입니다. 처음엔 100개의 단어로 시작했지만, 시간이 점차 지나며 단어는 몇만개로 늘어날 것이고, 여기서 선별된 100개의 단어를 reference vector라고 합니다.
두번째 방법으로 매우 많은 스팸 메일의 주소를 모으는건 어떨까요? 그러나 보통 스팸 메일을 하나의 경로로만 보내는 경우는 흔치 않기 때문에 실효적일거 같진 않습니다.
세번째 방법으로 메일 내용 속 이상한 단어들을 찾아내는 것입니다.
네번째 방법으로는 스팸 필터링을 피하기 위해 알파벳과 비슷한 모양의 문자를 섞어서 사용하는 이상한 스펠링의 단어를 찾아낼 수도 있습니다.
이외에도 스팸 메일을 분류하기 위한 다양한 방법들이 존재할 것입니다. 하지만 이중 제가 원하는 것은 스팸 메일을 가장 잘 분류할 수 있는 방법을 하나 선택하여 모델 학습에 이용하는 것입니다. 그러면 저중 제가 마음에 드는 한가지 방법을 선택하여 무작정 해보면 되는 것일까요?
이러한 상황에서 가장 좋은 방법들을 택하기 위해 각 방법의 오류를 체계적이고 수치적으로 분석해보는 것을 Error Analysis라 합니다.
Error Analysis
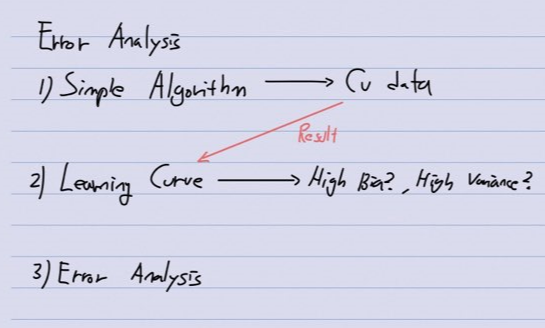
전반적인 머신러닝 시스템을 설계하기 위해 추천되는 접근법을 알아보겠습니다.
1) 아주 간단한 알고리즘을 단순하고 빠르게 구현하여 cv data에 이용하여 테스트를 돌려봅니다.
2) 그 결과를 Learning Curve 그래프로 표현해보고, High Bias나 High Variance는 아닌지 살펴보고 상황에 따라 데이터의 수와 feature의 수를 조정합니다.
3) 그리고 마지막에 이뤄지는 것이 Error Analysis입니다. 즉 Cv data를 적용했을 때 발생하는 오류를 우리가 면밀히 검토하면서 발생한 에러의 원인은 무엇이고 어떤 특징을 가지는지 분석하는 것입니다.
위 방식을 스팸 메일을 분류하는 예제에 구체적으로 적용해보겠습니다.
500개의 Cv data에서 알고리즘이 100개의 이메일을 잘못 분류했습니다. 그러면 우리는 잘못 분류한 이메일에 대해서
1) 이메일이 어떤 타입인지 2) 어떤 feature가 알고리즘이 이들을 올바르게 분류하는데 도움이 될지 생각해보는 것입니다.
Numerical Evaluation

한가지 더 고민해야할 것은 discount / discounts / discounted / discounting와 같이 비슷한 단어를 같은 단어로 처리할 것인가? 입니다.
우리가 이러한 상황에서 사용해볼 수 있는 것이 Stemming 즉 형태소 분석입니다. 예를 들어, universe와 university가 있을 때, 두 단어에서 공통된 'univers'를 뽑아내는 것이고, 여기에 가장 대표적인 알고리즘으로 Porter algorithm이 있습니다.
예를 들어 우리가 스팸 메일 분류에 stemming을 이용했을 때 Error는 3%이고, 사용하지 않았을 떄 5%라면 당연히 stemming을 사용해야 합니다.
또는 대소문자를 구별했을 때 Error가 3%고 적용하지 않았을 때 2%라면 적용하지 않는것이 좋습니다. 이렇듯 각 방법에 대한 Error를 도출해 비교하여 적용여부를 판단하는 것이 Error Analysis의 핵심이라고 할 수 있습니다.
Error Analysis를 할때는 Cv data를 이용해야함을 유의해야합니다.
Error Analysis : Skewed classes using Precision, Recall
이번에는 신용 카드를 이용한 거래 사기(Credit Froud)를 분류하는 시스템을 만들어보고자 합니다. 저는 Logistic regression을 이용하여 분류 알고리즘을 만들었고, Test data를 이용하여 성능을 측정해보니 Error가 1%밖에 나오지 않았습니다. 분명 수치상으로 저는 좋은 알고리즘을 만든 것처럼 보입니다.
그런데 Data를 보니 전체 거래에서 신용 사기는 0.5%에 불과했습니다. 그럼 제가 만든 알고리즘이 여전히 정확도가 높다고 말할 수 있을까요? 0.5%차이가 별거 아닐수도 있지만, 1%의 신용사기중 0.5%나 되는 신용사기를 검출해내지 못하는 알고리즘을 좋다고 할 순 없을거 같습니다.
이렇게 우리가 어떤 데이터를 분류할 때 전체 데이터 중 매우 작은 비율을 갖는 한쪽 데이터를 skewed class라고 합니다. 암 발병 여부 판단, 사이버 침입, 테러 행위 등을 예시로 들 수 있으며 우리가 후에 배울 Anomaly Detection과 밀접한 연관이 있습니다. 한가지 중요한 것은 우리가 이러한 skewed class는 분류(Classification)보단 검출(detection)이라는 개념으로 접근하는 것이 정확합니다.

Precision과 Recall은 이 Skewed classes에 대해 Error Analysis를 할 때 이용되는 개념입니다.우선 다음 네가지 개념을 신용사기를 예로 들어 설명해보겠습니다.
True Positive는 실제 데이터가 사기(=1)였는데, 예측값도 사기인 정확한 결과입니다.
True Negative는 실제 데이터가 정상(=0)이었는데, 예측값도 정상인 마찬가지로 정확한 결과입니다.
False Positive는 실제값은 사기인데 예측값은 정상인 경우입니다.
False Positive는 실제값은 정상인데 예측값은 사기인 경우입니다.
그리고 Precision과 Recall에 대한 공식입니다.
Precision(정확도)로 전체의 1% 신용사기 데이터를 예측값으로도 신용사기라고 얼마나 잘 예측했느냐입니다. 이는 False Positivie가 작아질수록 분모는 작아지는 구조이므로 Precision은 1에 가까울수록 좋습니다. Recall(검출율)로 모델이 신용사기라고 예측한 데이터 중 실제값도 신용사기인 데이터가 얼마냐 있냐이며, 역시 1에 가까울수록 좋습니다.
이렇게 설명드려도 종종 Precision과 Recall의 개념을 헷갈리는 경우가 있습니다. 이는 대부분의 사람들이 detect라는 개념을 전체 데이터에서 신용 사기를 검출한 경우로만 한정지어 생각하기 때문입니다. 즉 detection에는 실제값이 신용 사기인데 예측값이 신용 사기인 경우와 함께 실제값은 정상이지만 예측값이 신용 사기인 경우도 포함된다는 것입니다.
이처럼 Detection을 단순히 알고리즘의 출력(결과)임을 염두에 두고, detection이란 예측값이 신용 사기인 데이터라고 생각하시면, Precision과 Recall을 위와 같이 생각하면 개념이 명확해집니다.
Trading Off Precision and Recall

Precision과 Recall은 반비례 관계를 가집니다. Threshold는 True와 False를 나누는 기준선으로 Logisitc Regression의 경우 0.5였습니다. Threshold가 높아질수록 기준선이 높아지는 것이므로 True로 검출되기 까다로워집니다.

신용 사기 분류에서 이 threshold를 0.7로 크게 잡겠습니다. 그러면 기준선이 높아지니 Precision은 높아지겠지만, 그만큼 신용 사기 검출(여기엔 True Positive와 False Negative가 포함됩니다)이 줄어들기 때문에 Recall은 줄어듭니다.
반대로 threshold를 0.3로 작게 잡으면, 기준선이 낮아지니 신용 사기로 검출되기 쉬워졌습니다. 따라서 Precision은 줄어들고 Recall은 증가할 것입니다.

그러면 이 Precision과 Recall을 이용하여 어떻게 좋은 알고리즘인지 판별할 수 있을까요? 우선 Precision과 Recall을 평균내는 것은 위 세 번째 경우만 보더라도 좋은 경우가 될 수 없습니다.

우리는 F score를 사용할 것입니다. F score이 높을수록 알고리즘의 성능이 좋은 것이며, F score이 높아지기 위해서는 Precision과 Recall이 동시에 1에 가까워야합니다.
Data for Machine Learning
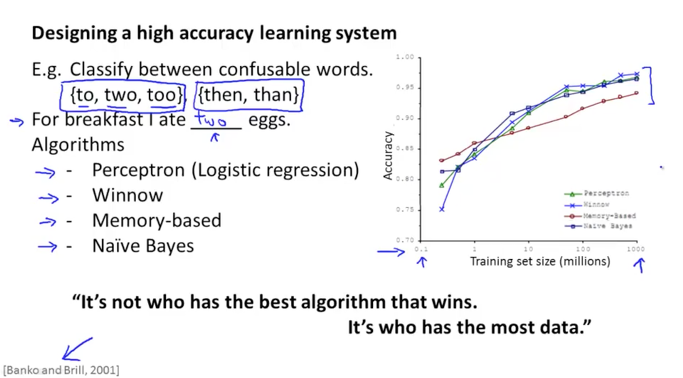
높은 accuracy를 가지는 모델을 디자인하려면 어떻게 해야할까요?
단어를 찾아 문장을 완성하는 머신러닝 알고리즘을 만든다고 했을 때 다양한 알고리즘들을 생각해볼 수 있습니다. 네가지 알고리즘 모두 성능에는 큰 차이가 없습니다. 다만 우리가 알 수 있는 것은 Dataset이 커질 수록 accuracy가 더욱 높아진다는 것입니다.
Data가 많은 것도 중요하겠지만, 결과 예측에 큰 영향을 미치는 좋은 정보(feature)를 갖는 것도 중요합니다. 결국 어떤 것이 중요한 정보인지를 판별하려면 해당 분야에 대한 지식(Domain)이 있어야 합니다.
신용 사기의 경우, 전반적인 금융에 대한 지식과 신용카드 시스템에 대한 이해가 이에 해당합니다. 실제로 많은 전문가들은 우리가 어떤 분야에 머신러닝을 적용하고자 할때 해당 분야에 대한 지식을 갖는것이 상당히 중요하다고 말씀하십니다.

결국 Dataset의 크기가 크다는 것은 Logistic Regression이나 Linear regression의 경우엔 feature가 많다는 것이고, Neural Network의 경우엔 Hidden Unit이 많다는 것입니다.
이렇게 Dataset이 크다면 알고리즘은 Low Bias(High Bias와 대조되는 개념)일 확률이 크기에 Training set의 Cost는 작을 것이며, Overfit되기도 어려워져 Test set의 Cost 또한 작을 것입니다.
요약
1) 머신 러닝 시스템을 디자인할 때, 가장 좋은 방법들을 택하기 위해 각 방법의 오류를 체계적이고 수치적으로 분석해보는 것을 Error Analysis
2) Error Analysis를 할때는 Cv data를 이용해야함을 유의해야합니다.
3) 우리가 어떤 데이터를 분류할 때 전체 데이터 중 매우 작은 비율을 갖는 한쪽 데이터를 skewed class, 이러한 skewed class는 분류(Classification)보단 검출(detection)이라는 개념으로 접근하는 것이 정확합니다.
4) Precision(정확도)로 전체의 1% 신용사기 데이터를 예측값으로도 신용사기라고 얼마나 잘 예측했느냐 / Recall(검출율)로 모델이 신용사기라고 예측한 데이터 중 실제값도 신용사기인 데이터가 얼마냐 있냐
5) Skewed class에서 알고리즘의 성능을 측정할 땐 F1 score를 사용한다. (Precision과 Recall 자체는 알고리즘의 성능을 대표할 수 없다.
6) Dataset이 커질 수록 accuracy가 더욱 높아진다
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [머신러닝 순한맛] SVM(Support Vector Machine)이란? - 2) Margin (3) | 2020.05.06 |
|---|---|
| [머신러닝 순한맛] SVM(Support Vector Machine)이란? - 1) Introduction (0) | 2020.05.05 |
| [머신러닝] 머신러닝 학습 시 고려해야 하는 것 : High Bias vs High Variance, Learning Curve (0) | 2020.05.03 |
| [머신러닝] 머신러닝 학습 시 고려해야할 것 : Test data와 Cv data란? (4) | 2020.05.03 |
| [머신러닝] 딥러닝의 시작 Neural Network 정복하기 2 (0) | 2020.05.01 |