시작하며
저번 포스팅에서는 SVM이 무엇인지 전반적으로 알아보는 시간을 가졌습니다. 그때 SVM이라는 것은 결국 Decision Boundary가 자신과 분류하는 데이터들 사이의 Margin이 클수록 안정적이고 균형적임을 강조했었습니다.
이번 포스팅에서는 SVM에서 핵심 키워드라고 할 수 있는 Margin에 대해 수학적으로 접근해보고, Margin을 키울려면 어떠한 조건이 필요한지 알아보겠습니다.
이번 포스팅은 아래 포스팅을 보고 공부하시면 더욱 효과적입니다.
https://box-world.tistory.com/25
[머신러닝 순한맛] SVM(Support Vector Machine)이란? - 1) Introduction
시작하며 오늘은 또 하나의 Classification 알고리즘인 Support Vector Machine(Large Margin Classification)에 대해 알아보겠습니다. 이번 포스팅은 아래 포스팅을 읽어보시고 공부하시면 훨씬 효과적입니다. ht..
box-world.tistory.com
Vector의 내적
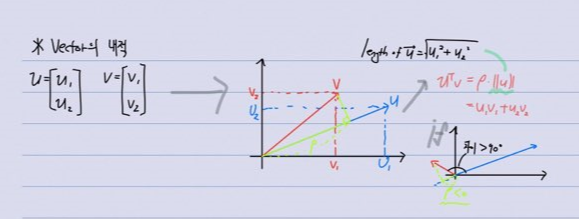
여기 2개의 vector u, v가 있습니다. 각 vector는 2개의 값을 갖습니다. 이때 v 벡터를 u 벡터에 투영해보겠습니다. 이때 투영된 벡터의 길이가 u 벡터와 v 벡터를 내적한 결과라고 할 수 있습니다.
이때 투영된 벡터의 길이를 p라고 하겠습니다. 그렇게 되면 U^Tv = p||u|| = u_1v_1+u_2v_2이라고 할 수 있으며, 이때 p는 *u와 v 벡터의 차이가 **90도가 넘어가면 음수, 그렇지 않으면 양수가 됩니다.
이때 $\left| u \right|$는 u 벡터의 euclidean length(Euclidean distance)로 벡터의 길이를 의미합니다. 따라서 $\left| u \right|$는 $\sqrt{u_1^2+u_2^2}$라고 할수도 있습니다.
그리고 두 벡터 u, v의 내적 $u^Tv$는 $u_1v_1+u_2v_2$이며, 이것은 $p*\left\| u \right\|$라고 할 수도 있습니다.
Decision Boundary
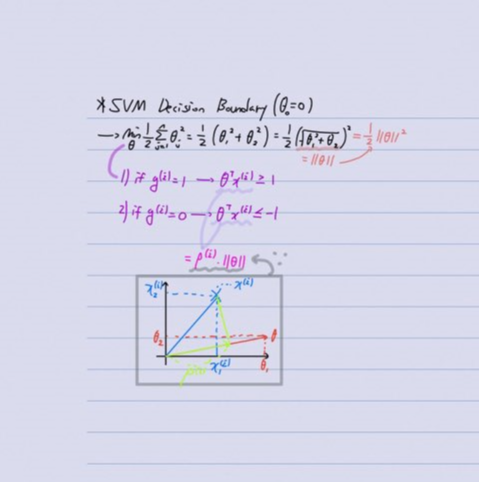
이제 방금 우리가 다룬 것을 SVM의 Decision Boundary에 적용해보겠습니다. 기존의 우리가 보았던 u, v 벡터를 각각 θ와 x에 대한 벡터로 생각하시고, 마찬가지로 각 벡터는 두개의 값을 가집니다. 우선 이해를 위해 $θ_0$는 0으로 놓겠습니다.
SVM의 Decision Boundary는 n개의 θ를 제곱하여 합한 값의 $\frac{1}{2}$이었습니다. 이것을 풀어서쓰면 $\frac{1}{2}(θ_1^2+θ_2^2)$와 같고, $x={\sqrt{x^2}}$를 이용하면 $\frac{1}{2}{\sqrt{(θ_1^2+θ_2^2)^2}}$라고 할 수 있습니다.
이때 $\frac{1}{2}{\sqrt{(θ_1^2+θ_2^2)^2}}$는 $\left\| θ \right\|$와 같아서 최종적으로 나온 $\frac{1}{2}*(\left\|θ\right\|)^2$가 Decision Boundary가 되겠습니다.
우리가 이전 포스팅에서 Cost를 최소화하기 위해서 $y^{(i)} = 1$이기 위해서는 $θ^Tx^{(i)} \ge 1$이어야 했습니다. 이때 $θ^Tx^{(i)}$이 $p^{(i)}*\left\|θ\right\|$와 같기 때문에 $p^{(i)}*\left\|θ\right\| \ge 1$이어야 한다고 해석할 수 있습니다. 반대의 경우 $y^{(i)} = 0$이기 위해서는 $p^{(i)}*\left\|θ\right\| \le -1$이어야 합니다.
따라서 위 그래프를 다시 표현하면 $θ^Tx^{(i)}$는 $p^{(i)}*\left\|θ\right\|$와 $θ_1x_1^{(i)}+θ_2x_2^{(i)}$와 같습니다.

이제 왼쪽 그래프처럼 대각선인 Decision Boundary가 있다고 생각해보겠습니다. 이때 이것과 직각으로 θ벡터가 생성 되고, 각 데이터들이 위에서 말한 x 벡터들이 됩니다.
이때 θ벡터에 o, x데이터를 투영하여 생성된 $p^(i)$의 길이가 굉장히 작다는 것을 보실 수 있습니다. 이것은 Cost를 최소화하기 위해서 $p^{(i)}*\left\|θ\right\|$가 1보다 크거나 -1보다 작기 위해서는 $\left\|θ\right\|$가 커야함을 시사합니다. 좀더 나아가 θ벡터의 길이가 커야한다는 것은 θ값이 커져야 한다는 의미이기 때문에 Cost함수가 $θ^2$의 합인 SVM입장에선 좋은 케이스가 아닙니다.
이번엔 오른쪽 그래프처럼 y축과 일치하는 Decision Boundary를 생각해보겠습니다. 이때 이것과 직각인 θ벡터가 생성되고 이는 x축과 일치합니다. 역시 마찬가지로 o, x 데이터를 투영하여 생성된 $p^(i)$를 보시면 그 길이가 상대적으로 큰값을 가지고 됩니다. 결국 이것은 $\left\|θ\right\|$가 상대적으로 작아도 된다는 것을 시사하게 됩니다. 그리고 이는 곧 θ값이 그만큼 작아진다는 의미가 되므로 비용을 최소화하기 위한 좋은 케이스가 됩니다.
정리하자면 Cost를 최소화하는데 있어서 $p$와 $\left\|θ\right\|$는 반비례 관계를 가짐을 알 수 있습니다. 여기에 p가 커진다는 것은 Decision Boundary와 data간의 margin이 커진다는 것과 같은 의미로 해석할 수 있습니다.
지금까지 우리가 본 예시들은 $θ_0$를 0으로 놓음에 따라 θ벡터가 원점을 지나는 경우를 관찰해 보았습니다. 만약이 $θ_0$가 0이 아니라면 원점이 아닌 다른 점을 지나는 벡터가 될것이고 그 지점에서 Margin이 큰 Decision Boundary를 만드려고 할 것입니다.
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [머신러닝 순한맛] SVM(Support Vector Machine)이란? - 4) Preview (1) | 2020.05.12 |
|---|---|
| [머신러닝 순한맛] SVM(Supprot Vector Machine)이란? - 3) Kernal (2) | 2020.05.11 |
| [머신러닝 순한맛] SVM(Support Vector Machine)이란? - 1) Introduction (0) | 2020.05.05 |
| [머신러닝] 머신러닝 시스템 디자인 하기 : Precision, Recall, F score (3) | 2020.05.04 |
| [머신러닝] 머신러닝 학습 시 고려해야 하는 것 : High Bias vs High Variance, Learning Curve (0) | 2020.05.03 |