시작하며
오늘은 또 하나의 Classification 알고리즘인 Support Vector Machine(Large Margin Classification)에 대해 알아보겠습니다.
이번 포스팅은 아래 포스팅을 읽어보시고 공부하시면 훨씬 효과적입니다.
https://box-world.tistory.com/13
[머신러닝] Logistic Regression 이해하기 1
시작하며 우리는 그동안 Supervised Learning 에서 회귀(Regression) 를 중점적으로 다뤘습니다. 이때 회귀 란 결과값을 예측하는 것이었습니다. 이제부터는 마찬가지로 Supervised Learning 중 하나인 분류(Class..
box-world.tistory.com
https://box-world.tistory.com/14
[머신러닝] Logistic Regression 이해하기 2
시작하며 저번 포스팅에선 Supervised Learning 중 하나인 Classification 에 대해 알아보고, 여기에 사용되는 Logistic Regression 의 기초를 공부하였습니다. Logistic Regression 이해하기 1 https://box-worl..
box-world.tistory.com
What is SVM?
SVM은 Logistic Regression이나 Neural Network보다 복잡한 non-linear한 함수를 처리하는데 훨씬 효과적입니다.
본격적으로 SVM을 알아보기 전 Logistic Regression에 대해 대략적으로 복습해보도록 하겠습니다.
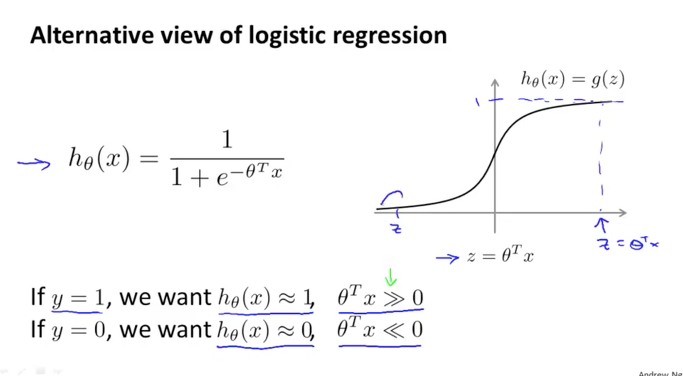
Logistic Regression의 가설함수 $h(x)$를 살펴보겠습니다. 실제값 $y=1$일때 $h(x)$가 1에 가까워져야하므로 $θ^Tx$도 0보다 큰 값이 될것이고, $y=0$일때 $h(x)$는 0에 가까워져야하므로 $θ^Tx$도 0보다 작은 값이 될것입니다. 이때 우리는 $θ^Tx$를 편의상 z라고 합니다.

이번엔 Cost 함수를 살펴보겠습니다. 이때 $y=1$일때는 공식의 앞부분만 남고 $y=0$일때는 공식의 뒷부분만 남는다는 사실을 우리는 알고있고 그때의 그래프는 왼쪽과 같습니다. 그런데 왼쪽의 그래프를 오른쪽의 그래프로 바꿔보겠습니다.
이때 $y = 1$일 때 $z > 1$이면 Cost가 0이고, 1보다 작으면 Cost가 점점 커지게 되는데 이를 $Cost_1(z)$이라고 칭하겠습니다. 그리고 $y = 0$일 때 $z < 1$이면 Cost가 0이고, 1보다 크면 Cost가 점점 커지게 되는데 이를 $Cost_0(z)$이라고 칭하겠습니다.
이제 Logistic Regression의 Cost 함수에서 SVM의 Cost 함수를 도출하기 위해 몇가지 단계를 조금 더 거쳐보겠습니다.

첫째는 기존 Cost 함수의 log부분을 $Cost_1(z)$와 $Cost_0(z)$로 바꾸어줍니다.
우선은 1/m을 지우겠습니다. 왜냐하면 우리의 목적은 결국 최적화인데, 상수인 1/m가 있든 없든 최소값은 항상 동일하기 때문입니다. 예를 들어 $\frac{1}{m} = 10$이라고 할 때, u의 값은 바뀌지 않는 것을 확인할 수 있습니다.
그리고 람다의 위치를 바꾸겠습니다. 기존에 정규화를 적용한 Logistic Regression의 Cost 함수는 'A+λ*B'의 형태인데 이것을 'C*A+B'의 형태로 변경하는 것입니다. 이때 C는 1/λ입니다. 기존에 B에 λ를 곱했다는 것은 A에 가중치를 두겠다는 것이고, 이 λ를A에 넘겼다는 것은 B에 가중치를 두겠다는 것입니다.

이렇게 Logistic Regression의 Cost 함수에서 몇가지 변경을 해주면 위와 같은 SVM의 Cost 함수가 정의됩니다. 이때 $θ^Tx > 0$일때 $h_θ(x)$는 1이고, 그렇지 않으면 0이 됩니다.
SVM에서 Margin이란?

SVM은 Large Margin Classification으로 불리기도 합니다. 왜 그런지 다시 한번 SVM을 살펴보겠습니다.
만약 $y=1$일 때, $Cost_1(z)$는 $θ^Tx$ > 1일때 0이 됩니다. 반면에 $y=0$일 때, $Cost_0(z)$는 $θ^Tx$ < -1일때 0이됩니다. 이때 우리가 주목해야할 점은 기존에 Logistic Regression의 Cost 함수는 0을 기준으로 나뉘었음에 반해, SVM은 1과 -1을 경계지점으로 하여 -1과 1사이에 Gap이 발생한다는 점입니다.

이제 C를 살펴보겠습니다. 만약 C=100000로 아주 큰 값이라고 해보겠습니다. 이때 Cost 값이 최소화되기 위해선 Cost함수가 포함되어있는 Σ가 0이 되어야 할 것입니다. 이를 위해선 $y=1$일때는 $z ≥ 1$이어야 하고 $y=0$일때는 $z ≤ -1$이어야 합니다.
이렇게 해서 Σ부분이 사라지게 되면 위처럼 뒷부분만 남게됩니다. 이것이 바로 Classification을 위한 Decision Boundary가 됩니다.

하나의 Dataset에 대한 Decision Boundary를 여러 케이스들이 존재할 수 있습니다. 그중에 특히 위 그래프의 검정색 라인은 안정적이고 균형적으로 Data을 분리하고 있습니다.

이때 검정색의 Decision Boundary가 dataset와 두는 일정한 거리 혹은 간격(Gap)을 Margin이라고 하고, 이것이 SVM이 Large Margin Classification이라고 불리는 이유입니다.

SVM은 데이터를 올바르게 분리하면서 Margin의 크기를 최대화하는 것이 중요합니다. 따라서 특정 그룹에서 혼자 동떨어져 있는 이상치(outlier)를 다루는 것이 중요합니다.
앞에서 봤던 똑같은 Dataset에 새로운 데이터가 추가된 상황을 생각해보겠습니다. 이 새로운 데이터는 누가봐도 outlier임을 알 수 있습니다.
이때 우리는 두가지 선택지가 있습니다. 첫째는 이러한 Outlier까지 철저하게 분리하는 Hard Margin입니다. 이 경우 데이터와 Decision Boundary 사이의 Margin이 매우 작아지며, 이런 Outlier를 모두 고려하며 Decision Boundary를 정하려 하면 Overfitting 문제가 발생할 수도 있습니다.
둘째는 Outlier들을 어느정도 margin안에 포함되게 하면서 무시하는 Soft Margin입니다. 이 경우 Margin은 커지지만 Underfit의 위험이 있습니다.
Hard Margin을 위해서는 C의 값을 크게 잡아야 하며, Soft Margin을 위해서는 C의 값을 작게 잡아야 합니다.
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [머신러닝 순한맛] SVM(Supprot Vector Machine)이란? - 3) Kernal (1) | 2020.05.11 |
|---|---|
| [머신러닝 순한맛] SVM(Support Vector Machine)이란? - 2) Margin (2) | 2020.05.06 |
| [머신러닝] 머신러닝 시스템 디자인 하기 : Precision, Recall, F score (0) | 2020.05.04 |
| [머신러닝] 머신러닝 학습 시 고려해야 하는 것 : High Bias vs High Variance, Learning Curve (0) | 2020.05.03 |
| [머신러닝] 머신러닝 학습 시 고려해야할 것 : Test data와 Cv data란? (2) | 2020.05.03 |