혁신을 할 때는 모든 사람들이 당신을 미쳤다고 할 테니,
그들 말에 준비가 되어 있어야 한다.
- 래리 앨리슨 (Oracle ceo) -
시작하며
우리는 저번 포스팅을 통해 Anomaly Detection의 전반적인 이해를 마쳤습니다. 이번 포스팅에서는 Anomaly Detection에서 발생할 수 있는 문제를 살펴보며, 이에 대한 해결책인 다변량 정규분포(Multivariate Gaussian Distribution)에 대해 공부해보겠습니다.
이번 포스팅은 아래 포스팅들을 통해 Anomaly Detection을 이해하고 보시면 더욱 효과적입니다.
https://box-world.tistory.com/35
[머신러닝 순한맛] 이상 탐지(Anomaly Detection)이란?
"기술에는 품위와 친절이 녹아있어야 한다." - 팀 쿡 - 시작하며 여기 암을 조기에 발견할 수 있는 인공지능을 만드는 개발자가 있습니다. 그 개발자는 우여곡절끝에 정확도 99.00%를 자랑하는 머��
box-world.tistory.com
https://box-world.tistory.com/36
[머신러닝 순한맛] 이상 탐지(Anomaly Detection) vs Classification in Supervised Learning
실패에 대해 걱정하지 마라. 한번만 제대로 하면 된다. - 드류 휴스턴(Dropbox 공동 창업자) 시작하며 우리는 저번 포스팅에서 Anomaly Detection이란 무엇이며,이를 위한 알고리즘의 작동 원리까지 공��
box-world.tistory.com
Multivariate Gaussian Distribution
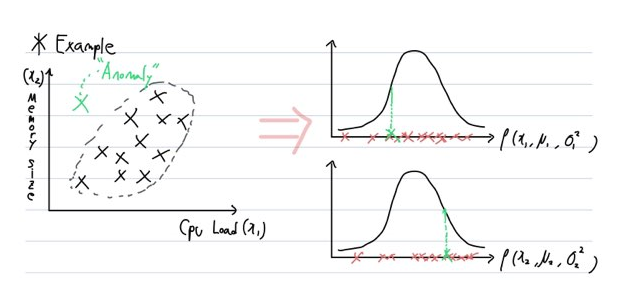
위 그림은 CPU 연산량 $(x_1)$에 따라 메모리 사용량 $(x_2)$을 측정하는 Dataset입니다. 여기서 Anomaly Detection을 사용하고자 각 feature를 일반적인 가우시안 분포(Gaussian Distribution)으로 나타내자 문제가 발생하였습니다.
보시다시피 녹색 데이터는 Anomaly Data임이 분명한데, 이를 일반적인 '2차원 가우시안 분포'로 나타낼 때는 $ε$보다 큰 값을 가지게 되어 정상적인 데이터로 분류됩니다. 이를 해결하기 위해 나온 것이 '다변량 정규분포(Multivariate Gaussian Distribution)'입니다.
우리가 지금까지 배운 Anomaly Detection 알고리즘은 가장 보편적으로 사용되는 'Original Model'입니다. 사실 방금 문제를 'Multivariate Gaussian Distribution' 사용없이 '새로운 feature를 추가하여 해결하는 방법'도 있으나, 새로운 feature를 사용자가 직접 추가해야한다는 점에서 불편하고 정확도가 떨어지기에 좀 더 formal한 방법을 사용하여 해결하고자 하는 것입니다.
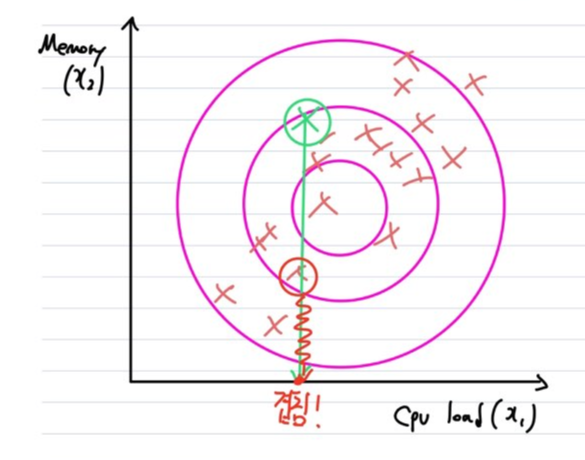
'Multivariate Gaussian Distribution'은 한마디로 이차원에서 존재하던 정규분포를 다차원 공간으로 확장한 것입니다. 문제가 되는 Dataset에서 Anomaly 데이터를 검출하지 못했던 이유는 '이차원 정규분포'에서 데이터를 바라보기 때문에 녹색 데이터 그리고 비슷한 위치에 존재하는 빨간색 데이터가 사실상 동일한 위치에 있는걸로 보이기 때문입니다. 따라서 이를 3차원 이상으로 확장하여 이를 보완하고자 하는 것입니다.

'Multivariate Gaussian Distribution' 에 사용되는 공식은 위와 같습니다. 여기에는 두가지 parameter가 등장하는데, $μ$는 n 개의 feature를 나타내는 n차원 vector이고, $Σ$는 공분산 행렬(covariance matrix)로 $n * n$차원 행렬입니다. 그리고 $|Σ|$은 sigma의 절대값으로 뒤에 나올 sigma 값을 결정합니다. 한가지 주의할 점은 각 feature에 대한 가우시안 분포를 구하여 곱하는 구조가 아닌 공식에 parameter를 대입하여 한번에 $p(x)$를 도출합니다.
PCA 알고리즘에서 이용되는 'covariance matrix'는 간단히 말하자면 데이터가 어떻게 퍼져있는가에 대한 행렬입니다. PCA에서 이것이 이용됐던 이유는 기존 데이터의 분포와 성질을 최대한 변화시키지 않으면서 낮은 차원에 mapping하기 위해서 였습니다. 따라서 'Multivariate Gaussian Distribution'에서도 2차원에서 나타나던 데이터의 분포를 최대한 변화시키지 않으면서 이를 다차원으로 확장시키기 위해 공분산 행렬을 이용하는 것입니다.
PCA 알고리즘이 궁금하신 분은 아래 포스팅을, 공분산 행렬에 대해 더 궁금하신 분은 아래 두번째 포스팅을 참고해주세요
https://box-world.tistory.com/33
[머신러닝 순한맛] PCA(Principal Component Analysis) 알고리즘이란?
″성공의 핵심 요소는 인내심이다.” -Bill Gates- 시작하며 우리 저번 포스팅에서 Data Compression 또는 Dimentianality Reduction의 기본적인 원리를 알아보았습니다. 이번 시간에는 이러한 원리를..
box-world.tistory.com
https://angeloyeo.github.io/2019/07/27/PCA.html
주성분 분석(PCA) - 공돌이의 수학정리노트
angeloyeo.github.io

이제 'Multivariate Gaussian Distribution'을 기하학적으로 이해해보겠습니다. 위 그림은 두 개의 parameter $μ$과 $Σ$에 따른 그래프의 변화입니다. $μ$가 고정된 상태에서 $Σ$ 행렬의 값이 커질수록 원의 크기가 커지면서 데이터가 퍼지게 됩니다. 반대로 값이 작아질수록 원의 크기가 작아지면서 데이터가 뭉치게 됩니다.
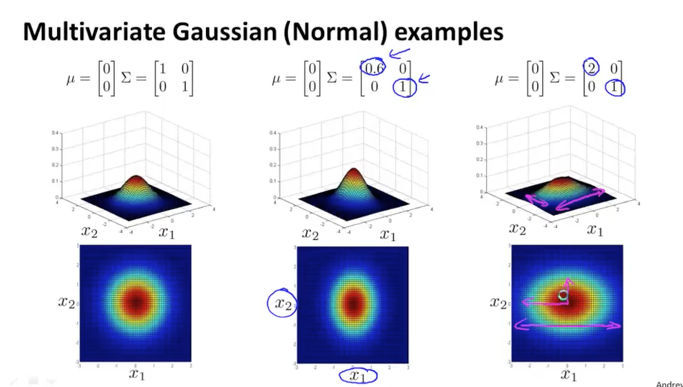
$Σ$ 행렬에서 1행 1열의 element는 $x_1$의 분산(퍼지는 정도)를 2행 2열은 $x_2$의 분산을 결정합니다. 따라서 $x_2$의 분산을 고정시켜놓고 $x_1$의 분산을 줄이면 $x_1$ 관점에서 원이 홀쭉해지고, 분산을 늘리면 원이 뚱뚱해짐을 확인할 수 있습니다.

반대로 $x_1$의 분산을 고정하고 $x_2$의 분산을 변화시켰을 때 그래프의 변화입니다.
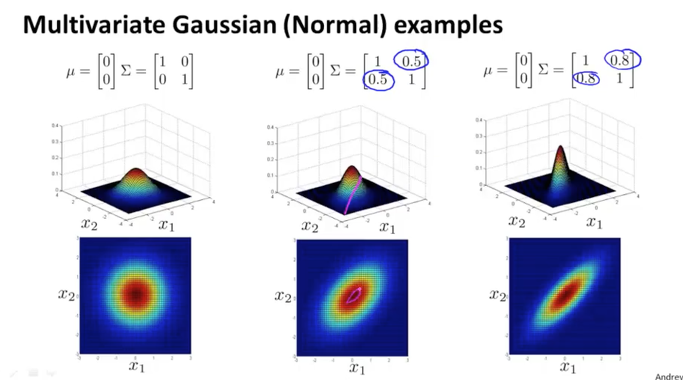

$Σ$ 행렬에서 1행 2열과 2행 1열의 element는 $x_1$과 $x_2$의 상대적인 위치관계에 대한 분산을 조절합니다. 즉 분산 값이 커질수록 데이터가 퍼지게 되니 원은 길게 홀쭉해지게 됩니다. 반대로 분산이 작아질수록 원은 납작하게 홀쭉해집니다.

$μ$는 'Multivariate Gaussian Distribution'의 중심 위치를 결정합니다.

어쨌든 몇가지 예시를 통해 parameter 값을 조정하여 'Multivariate Gaussian Distribution'가 어떻게 변하는지를 보았고, 이것을 이용하여 Anomaly Data가 확실히 검출될 수 있도록 해야합니다.

이제 Cpu / Memory Dataset에서 발생했던 문제를 해결해보겠습니다. 우선 Dataset의 평균과 분산을 이용하여 $μ$와 $Σ$를 구하고, 이를'Multivariate Gaussian Distribution' 공식에 대입하여 $p(x)$를 도출합니다. 이때 $ε$보다 작은 데이터는 Anomaly 데이터가 될 것입니다.
이제 데이터의 분포를 살펴보면 정상적인 데이터들은 길쭉한 원의 형태로 분포되어 있고, 녹색 데이터만 동떨어져 확실히 분류가 됨을 볼 수 있습니다.
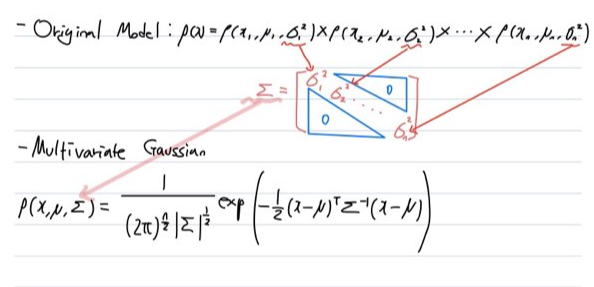
우리가 기존에 Original Model에서 사용했던 $p(x)$ 공식은 사실상 'Multivariate Gaussian Distribution'의 $p(x)$와 동일하다고 봐도 무방합니다. 왜냐하면 Original $p(x)$에서 각각의 feature에 대한 $σ^2$을 모두 모아 행렬로 표현하면 'Multivariate Gaussian Distribution'의 $p(x)$의 $Σ$가 되기 때문입니다.

마지막으로 두 모델의 장단점을 비교해보겠습니다.
* Original Model
- (단점) 문제가 발생했을 때, 사람이 직접 오류를 분석하고 feature를 추가해야 한다는 점에서 리스크가 있습니다.
- (장점) 연산 Cost가 매우 저렴하기 때문에 보통 보편적으로 많이 사용합니다. 그래서 feature가 100000개라도 부담없이 사용하며, training set이 100개정도로 매우 작아도 Anomaly Detection이 가능합니다.
* Multivariate Gaussian Distribution
- (단점) $Σ$는 $n*n$ 행렬입니다. 따라서 연산 과정에서 이것의 inverse를 계산하는 cost는 매우 크기 때문에 dataset이 100000개 이상일 경우 사용하기 적절치 않습니다.
- inverse를 계산해야하기 때문에 $Σ$가 'non-invertible'이면 안됩니다. 따라서 이를 방지하기 위해 중복된 feature가 있다면 제거해야 합니다. 그리고 반드시 data의 개수가 feature의 수보다 10배 이상은 클때 사용이 가능합니다.
- (장점) 특정 조건에서만 사용이 가능하지만, 문제 발생 시 사람이 직접 feature를 추가하지 않아도 됩니다.
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [머신러닝 순한맛] 순환 신경망(RNN)이란? (3) | 2020.05.27 |
|---|---|
| [머신러닝 순한맛] CNN(Convolutional Neural Network)란? (0) | 2020.05.25 |
| [머신러닝 순한맛] 이상 탐지(Anomaly Detection) vs Classification in Supervised Learning (0) | 2020.05.24 |
| [머신러닝 순한맛] 이상 탐지(Anomaly Detection)이란? (8) | 2020.05.22 |
| [머신러닝 순한맛] PCA(Principal Component Analysis) 알고리즘이란? (2) (1) | 2020.05.21 |