당신이 두려워하는 일을 매일 하라
- 엘리너 루즈벨트 -
시작하며
10년 후에 우리의 삶을 송두리째 바꿀 단 하나의 기술을 꼽으라 하면 저는 '자율주행'이라고 답할 것입니다. 현재 IT 산업 전반적으로 자율주행 자동차 상용화를 위해 천문학적인 금액을 투자중입니다. 그리고 이러한 자율주행 기술 구현을 위해 핵심이 되는 기술이 바로 '컴퓨터 비전(Computer vision)'입니다.
이번 포스팅에서는 이러한 컴퓨터 비전 분야에서 이미지 분석을 위해 가장 보편적으로 사용되는 'CNN(Convolutional Neural Network)'에 대해 공부해보겠습니다.
이번 포스팅은 아래 포스팅을 통해 딥러닝(Deep Learning)을 이해하고 공부하시면 더욱 효과적입니다.
https://box-world.tistory.com/17
[머신러닝] 딥러닝의 시작 Neural Network 정복하기 1
시작하며 우리는 저번 포스팅에서 Overfitting을 다루며 배웠던 'non-linear classification' 에서, feature가 두개일 때 위와 같이 Decision Boundary를 표현해보았습니다.. Overfitting https://box-world.tist..
box-world.tistory.com
CNN : 등장 배경
CNN이란 이미지 분석을 위해 사용되는 가장 유명한 딥러닝 알고리즘 중 하나이며, 핵심은 바로 이미지의 패턴(pattern)을 분석하는 것입니다. 그 이유는 CNN의 시초를 이해하면 알 수 있습니다.

1959년, 고양이가 어떻게 이미지를 인식하는지 알아보기 위해 한 실험을 진행하였습니다. 보통 사람이 이미지를 볼 때는 각 뉴런들이 각 이미지의 서로 다른 부분적인 조각을 담당합니다. 즉 하나의 이미지를 인지한다는 건 여러 개의 입력이 각 뉴런에 들어옴으로써 이루어진다고 할 수 있고, 이것이 CNN의 기본 아이디어입니다.
CNN : 작동 원리
이제 본격적으로 CNN의 작동 원리에 대해 알아보겠습니다.
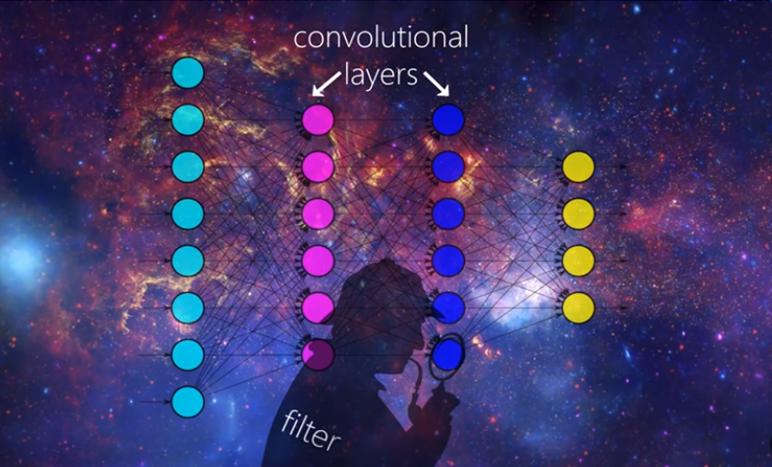
우선 2개의 Convolutional Layer로 이루어진 'Neural Network'가 있습니다. Hidden Layer라고도 부르는 이 두개의 Convolutional Layer가 바로 CNN Neural Network의 핵심이 됩니다.
Convolutional Layer가 바로 CNN 이미지 분석의 핵심인 '패턴 분석'을 담당합니다. 그리고 이러한 패턴 분석을 위해 쓰이는 도구가 'Filter'입니다.
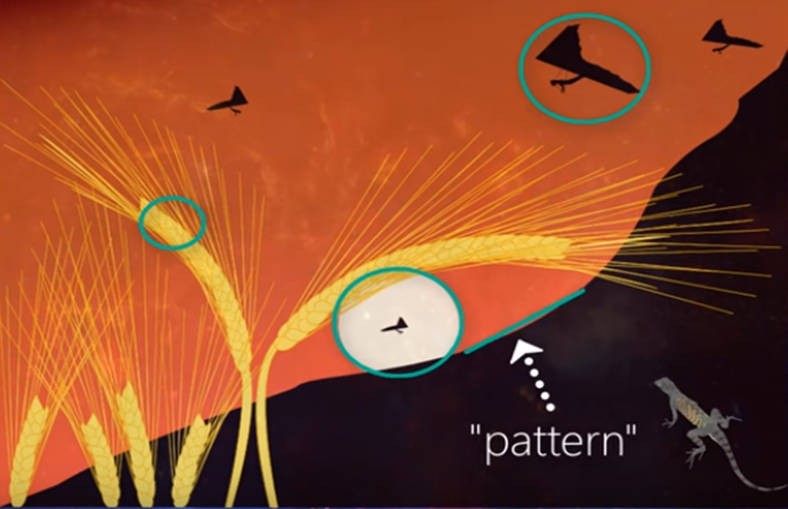
여기 이미지를 보면 언덕, 모양, 텍스쳐 등 이미지를 구성하는 다양한 '오브젝트(object)'들이 있습니다. 이때 'Filter'가 발견 하는 패턴은 Object를 구성하는 Edge, Corner, Circle 등이 될 수 있습니다. 자세한 작동원리는 조금 있다 설명드리겠습니다.
이때 Neural Network가 깊어질수록 Input으로 들어간 이미지는 더 많은 Convolutional Layer를 거치게 되면서, Filter가 발견하는 패턴은 더욱 구체화됩니다. 즉 첫 Layer에서 Filter가 발견한 패턴이 Edge, Corner, Circle 등이었다면 이것이 점점 깊어질수록 눈, 귀, 머리카락, 새들의 털, 부리 등 훨씬 구체적인 패턴을 발견할 수 있는 것입니다.
CNN : Filter의 역할
그러면 이제부터 Convolutinal Layer(Conv Layer)와 Filter가 네트워크안에서 어떤식으로 작동하는지 알아보겠습니다.
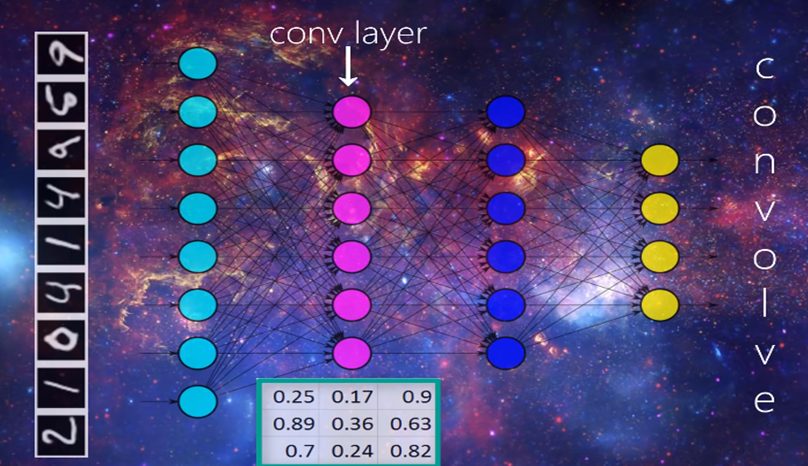
우선 Input Layer의 각 Unit에 사람이 손으로 쓴 숫자 이미지를 넣어보겠습니다. 이렇게 Input Layer로 받아들인 이미지는 다음 Conv Layer에 전달됩니다. 이때 각 Conv Layer에는 Filter가 존재하게 되고, Filter의 개수는 여러 개일 수 있습니다.
Filter란 Input 이미지보다 훨씬 작은 행렬로써 사용자가 몇 개의 row와 column을 가질지 정할 수 있고, 그 안의 숫자값들은 random으로 초기화되어 있습니다. 예를 들어 위 그림처럼 3x3 Filter가 있다고 할 때, 이것은 Input으로 들어온 이미지를 3x3 단위로 차례대로 돌아다니게 되며 이것을 'Convolving'이라고 부릅니다.


예를 들어 왼쪽 그림처럼 Input으로 받은 이미지가 있을 때, 이미지를 구성하는 행렬안의 숫자들은 이미지를 구성하는 픽셀(Pixel)을 뜻합니다. 그리고 오른쪽 그림에서 보이는 3x3 행렬이 우리가 사용할 Filter이고, 우선 갯수는 하나로 설정하겠습니다.
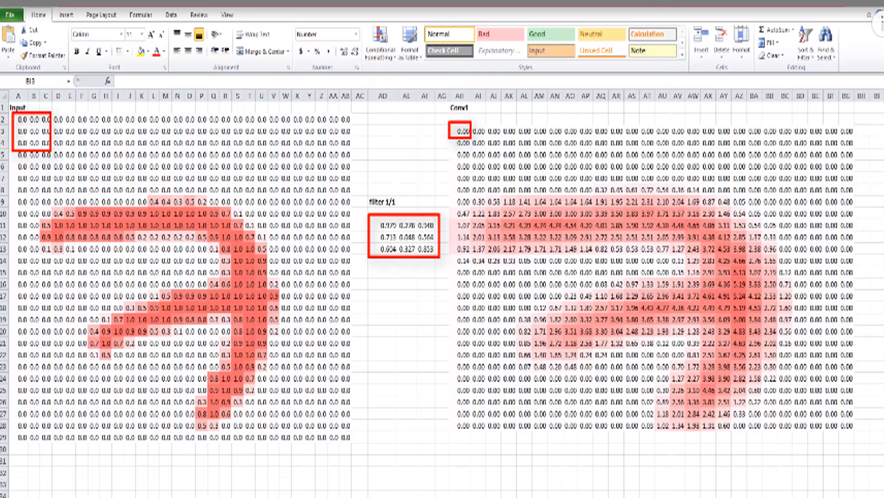
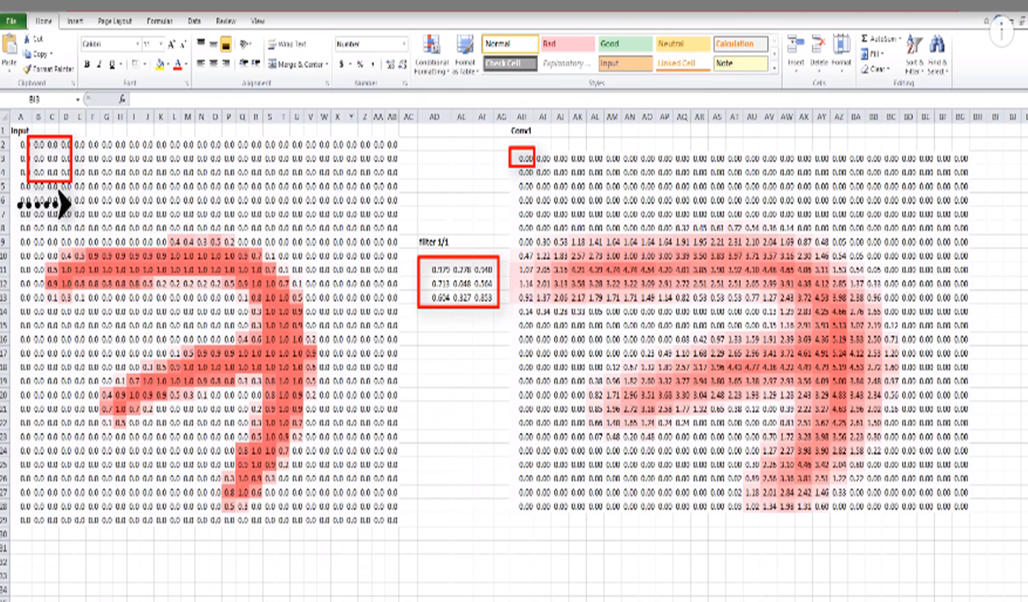
그러면 맨 처음 이미지에 3x3 Filter를 갖다댔을 떄 나온 특정 값(Dot)을 오른쪽 행렬 내 하나의 Element로 저장 합니다. 이때 이 픽셀이 흑백일 경우, Dot은 2차원이지만, 컬러일 경우는 RGB가 고려되기 때문에 3차원입니다.
그 다음 Filter는 오른쪽 그림과 같이 한칸 단위로 반복적으로 이동하면서 Dot을 뽑아냅니다. 이렇게 우리가 지정한 Filter가 Input 이미지의 전 영역을 Convolving한 후 나타난 결과가 오른쪽 이미지인 것입니다. 즉 이것은 첫 Conv Layer가 Input layer에서 받은 이미지를 통해 출력한 Output으로 다음 Conv layer의 Input으로 넘어가게 됩니다.

보통 Filter에서 나오는 특정 값(Dot)은 Input 이미지의 3x3 행렬을 $Wx + b(=θx + b)$에 대입하여 도출됩니다. 이때 $Wx + b$을 Relu 함수에 넣어줄 수도 있습니다. (참고로 딥러닝에서는 $θx + b$보단 $Wx + b$이라고 일반적으로 표현합니다.)
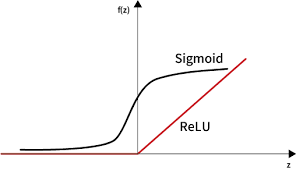
Relu 함수에 대해서 간단하게 설명드리자면, 우리가 Logistic Regression에서 사용하는 sigmoid 함수를 생각해보면 중간의 기울기는 0보다 매우 크지만 양옆으로 갈수록 0에 가까워지는걸 알 수 있습니다.
이렇게 양 옆으로 갈수록 0에 가까워지는 특성은 네트워크가 깊어질수록 Gradient가 0에 가까워져 데이터가 소멸이나 손실이 되어 우리가 원하는 학습을 못하는 결과가 일어납니다. 따라서 Relu 함수를 통해 이러한 데이터의 손실을 막을 수 있습니다.
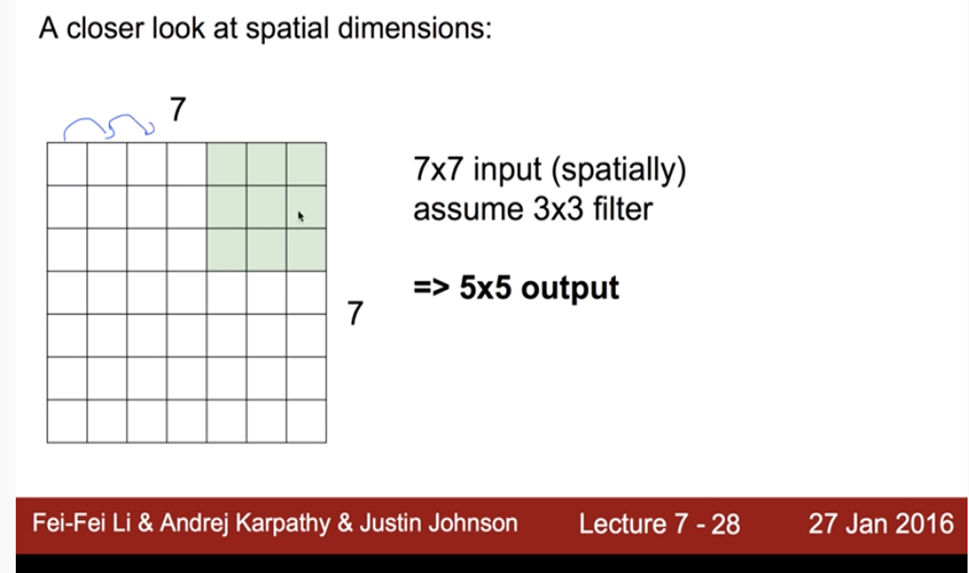

왼쪽 그림처럼 7x7 이미지에 하나의 Filter를 Stride를 1로 설정하여 이미지 전체를 Convolving했을 경우, output 사이즈는 5x5가 됩니다. 이때 Stride란 Filter를 한번 움직였을 때 이동하는 칸(Pixel)을 의미합니다. 오른쪽 그림에서는 Input 이미지와 Stride에 따른 Output Size의 크기를 공식으로 표현한 것입니다.

근데 Filter를 Convolving할 때, Stride가 커질수록 Output Size가 작아지게 됩니다. 즉 정보가 손실된다는 뜻 입니다. 그래서 이러한 정보의 손실을 막기 위해 사용되는 것이 패딩(Padding)입니다.
'Padding'은 위 그림처럼 이미지를 0으로 둘러싸줍니다. 이렇게 하면 이미지가 지나치게 작아지는걸 막을 수 있고, 혹은 가장자리가 0임을 이용하여 모서리라는 것을 알려줄 수도 잇습니다. 또한 Padding을 적용하면 Output Size가 줄어들지 않고, Input Size와 동일하게 유지됩니다.

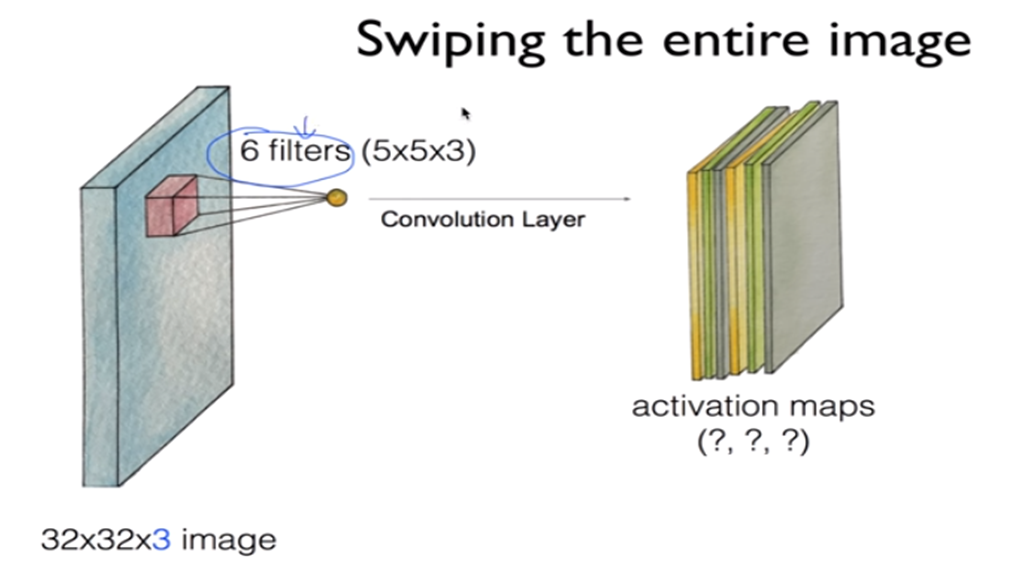
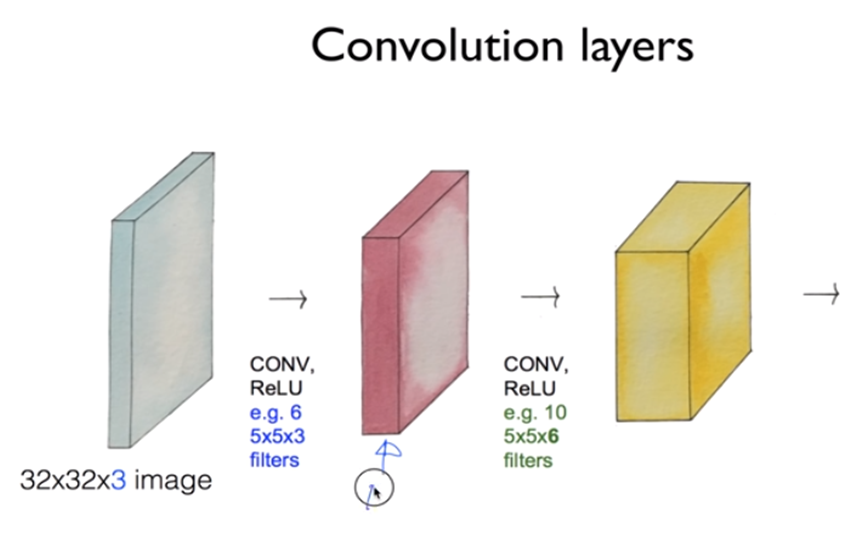
이제 Conv Layer를 어떻게 만드는지 알아보겠습니다. 오른쪽 그림같이 하나의 Filter를 거쳐 나온 output을 activation map이라고 합니다. 이떄 Filter가 여러개 있으면 중앙 이미지와 같이 activation map도 여러개가 있을 것이고 오른쪽 그림같이 이를 합치면 하나의 Conv Layer를 만들 수 있습니다.

또 하나의 개념인 Pooling에 대해서 살펴보겠습니다. 여기 4x4의 이미지를 2x2 filter를 이용하여 stride 2로 Convoving 했을때 색깔별로 영역을 나눌 수 있는데 Pooling은 저 색깔로 구분된 각 영역에서 특정값 하나를 그대로 뽑아 오는 것입니다. 가장 흔하게 쓰이는 것은 Max Pooling으로서 최대값을 뽑아오는 것입니다.

만약 하나의 Layer에 Filter가 여러 개라면 이런식으로 하나하나씩 Pooling 한다음 합치면 됩니다.
Pooling의 목적은 overfitting을 막기 위함입니다. 하나의 Pixel은 하나의 Feature에 해당합니다. 예를 들어 96x96짜리 image에 8X8 400개의 filter를 넣는다고 하면 한 필터당 7921개의 feature를 가지는 output이 나오는데, 이런 것이 무려 400개가 있는것입니다. 따라서 너무 많은 Feature로 발생할 수 있는 Overfitting을 방지하고자 Pooling을 사용하는 것입니다.
지금까지 우리가 본것은 하나의 Layer에서 Filter가 어떤 역할을 하는지 보여드린 것이고, 이제 Filter가 Conv Layer를 통과하면서 어떻게 패턴을 분석하는가에 대해 알아보겠습니다.

우선 사람이 손으로 쓴 숫자 7을 나타내는 이미지가 있고, 3x3 Filter 4개가 있습니다. 즉 기존 예시들과 다르게 Filter가 여러개라는 것을 유의하셔야 합니다.
이 Filter안의 값에서 -1은 검은색, 1은 하얀색, 0은 회색을 뜻합니다. 그리고 아래 보이는 4개의 이미지가 각 Filter를 Convoving한 Output입니다. 각 Filter가 발견한 패턴은 두가지로 구분할 수 있습니다. 첫번째는 4가지 Filter가 공통적으로 발견한 이미지의 가장자리 즉 Edge입니다. 그리고 두번째가 밝게 보이는 하얀색 부분입니다.
7을 3차원으로 바라보았을 때, 첫번째 Output의 경우 위에서 바라봤을 때 보이는 패턴을 / 두번째는 왼쪽에서 / 세번째는 아래에서 / 네 번째는 오른쪽을 인식하고 있습니다. 이해하기 어렵다면 각 방향에서 손전등을 비췄다고 생각하시면 됩니다.
이것은 하나의 Conv Layer를 통과시켰을 때의 결과이고, 더 많은 Layer를 통과시킬수록 구체적인 패턴을 발견할 수 있습니다.

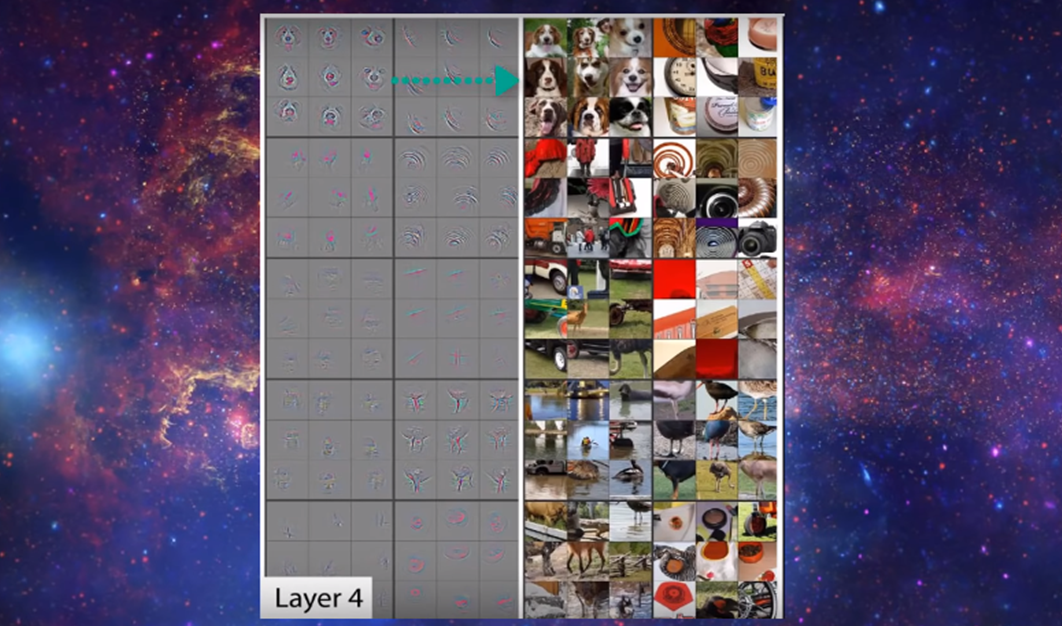
예를 들어 위에서 여섯번째 3x3 Output은 원을 발견하였고, 마지막 Ouput은 corner를 발견하였고, 이것보다 더 우리가 레이어를 통과시키면 동물 개와 같이 훨씬더 복잡한 모양의 패턴도 알아낼 수 있습니다.
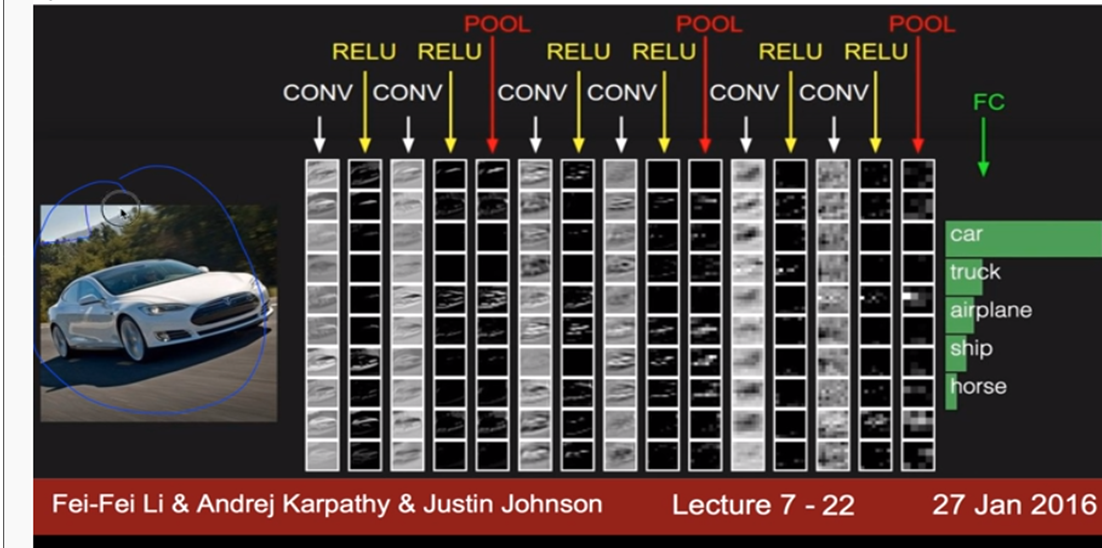
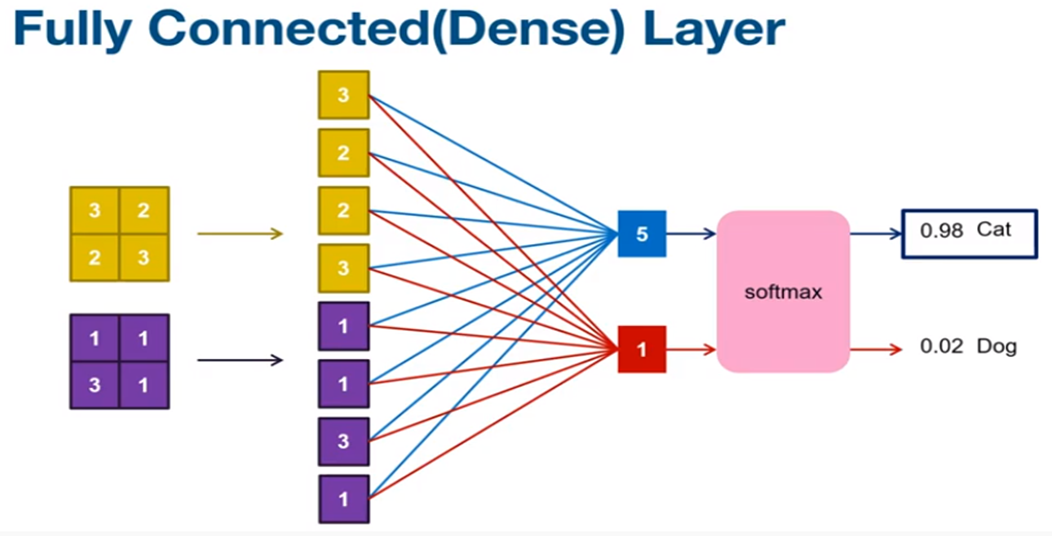
이제 또 다른 예시를 보면서 최종적으로 CNN을 정리해보겠습니다. 우선 Layer는 패턴을 분석하기 위한 Conv Layer, 데이터 손실을 방지하기 위한 Relu Layer, overfitting을 방지하는 Pooling Layer 등을 이용하여 네트워크를 구성합니다. 그리고 마지막에 FC Layer라는 것을 이용하여 최종적으로 Input 이미지가 무엇인지 분류(Classification)를 합니다.
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [ 핸즈온 머신러닝 2판 ] Linear Regression 속 Regularization이란? (0) | 2020.09.30 |
|---|---|
| [머신러닝 순한맛] 순환 신경망(RNN)이란? (3) | 2020.05.27 |
| [머신러닝 순한맛] 다변량 정규분포(Multivariate Gaussian Distribution) in 이상 탐지(Anomaly Detection) (1) | 2020.05.24 |
| [머신러닝 순한맛] 이상 탐지(Anomaly Detection) vs Classification in Supervised Learning (0) | 2020.05.24 |
| [머신러닝 순한맛] 이상 탐지(Anomaly Detection)이란? (8) | 2020.05.22 |