모든 경험에는 가르침이 있다
- 브라이언 트레이시 -
시작하며
과거를 통해 미래를 예측하는 능력은 누구나 갖고 싶어하는 것입니다. 하지만 오늘날 딥러닝 분야에서는 이러한 예측 능력을 수학적으로 구현하여 미래에 한발짝 다가가고자 하는 알고리즘이 있습니다. 바로 RNN(Recurrent Neural Network)입니다.
이번 포스팅에서는 자연어 처리(NLP), 주가 예측 등 폭넓게 사용되는 기본적인 RNN에 대해 알아보겠습니다.
RNN's Basic Idea
여기 네 개의 단어가 있습니다.

'I'는 주어, 'work'는 동사, 'at'은 전치사, 'google'은 명사라는건 대부분 알고 있습니다. 좀 더 구체적으로 들여다보자면 주어인 'I'가 왔기 때문에 그 뒤는 동사일 것이라고 자연스럽게 예측했고, 전치사 'at'이 왔기 때문에 그 뒤는 명사가 올것이라고 추론할 수 있었던 것입니다. 이러한 일련의 추론 과정을 수학적으로 모델링한 것이 바로 'RNN'입니다.
RNN의 구조
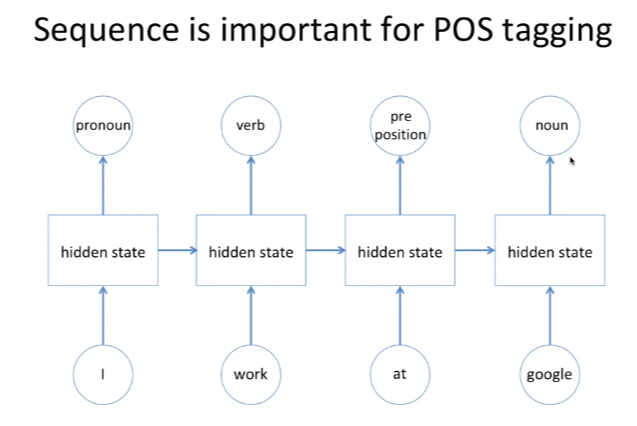
방금 보았던 예시를 4개의 단어를 Input으로 받아 품사가 무엇인지 Output으로 알려주는 RNN으로 다시 표현해보겠습니다. Input은 동시가 아닌 순차적으로 들어오며, 'I'는 hidden state라는 것을 거쳐 '주어'라는 것을 미리 알고 있다고 가정합니다.
그러면 'I' 다음 'work'를 Input으로 받는데, 이때 hidden state는 'work' 뿐만 아니라 이전 'I'에 대한 데이터를 이전 hidden state를 통해 받아 '동사'라고 판단하게 됩니다.
마지막으로 'google'이 들어왔을 때는 'google'과 함께 'I','work','at'에 대한 정보를 함께 조합하여 'google'이 명사일 확률이 높다고 결론을 내리게 됩니다.
이처럼 RNN은 Hidden state가 방향을 가진 Edge로 연결되어 순환구조를 이루는 인공신경망의 한 종류를 의미합니다. 그리고 이는 문장과 같은 'Sequence Data'를 분석하는데 유용하며, Input과 Output의 길이에 제약받지 않고 유연한 구조를 가질 수 있다는 점이 장점입니다.
이제 예시는 접어두고 Input은 $x_i$, Output은 $y_i$, hidden state는 $h_2$로 설정하고 구체적으로 구조를 살펴보겠습니다.

갑자기 등장한 $W_{xh}$, $W_{hh}$때문에 놀랐셨을텐데, 이것은 우리가 그동안 자주 봐왔던 가중치입니다. 결국 큰 맥락에서 딥러닝의 일종인 'RNN'은 이전의 Input 데이터들을 반영하여 현재의 Input 데이터가 무엇인지 판단하는데, 이때 판단의 정확도를 높이기 위해 여타 딥러닝처럼 가중치인 $W$를 최적화하는 매커니즘을 가지고 있습니다.

RNN은 이전의 데이터를 반영한다는 것을 $+$를 이용해 수학적으로 표현합니다. 예를 들어 위 그림에서 Input으로 $x_2$가 들어왔을 때 hidden state는 $x_2$ 그리고 이전 hidden state를 통해 $x_1$를 받아 Output을 출력하게 됩니다.
이때 각 $x_2$은 가중치 $W_{hh}$가, $x_1$은 가중치 $W_{xh}$가 곱해지고 여기에 Bias term인 'b'까지 더해져 만들어진 $$W_{hh}*(x_2) + W_{xh}*(x_1) + b$$는 활성 함수(activation function)인 $tanh$를 거쳐 최종적인 $y_2$를 도출하게 됩니다.( 활성 함수 = 가설함수 $h(x)$ )
이때 $h(x)$의 형태가 우리가 일반적으로 써오던 $Wx + b$가 아닌 $tanh$인 이유가 중요합니다. 만약 위 그림에서 4개의 hidden state에 $tanh$ 대신 $Wx + b$가 들어있다면, $y(x) =h(h(h(h(x))))$인데 이는 $y(x) = c*c*c*c*x$로써 사실상 결과값은 일차함수로 기존과 다를것이 없습니다. 따라서 딥러닝의 장점을 살려주기 위해서는 활성함수로 선형 함수가 아닌 '비선형함수'를 사용해야합니다.
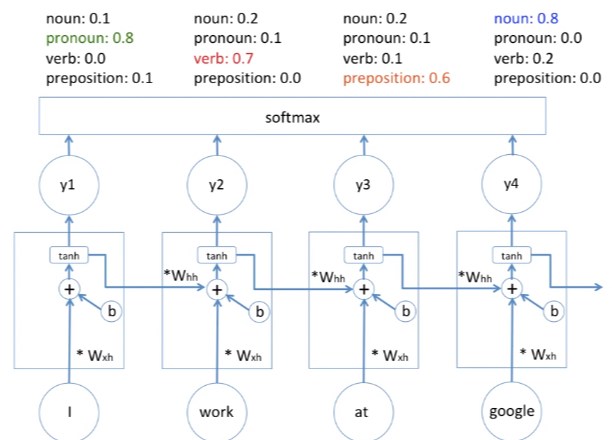
이제 각각 도출한 $y$값을 softmax에 넣으면 각 단어가 어떤 품사에 해당할지를 확률값으로 알려주고 이중 제일 확률이 높은 값이 예측값이 됩니다.

이제 남은 것은 '최적화(Optimization)'입니다. 최적화란 예측값과 실제값의 Cost를 줄여나가는 과정을 의미합니다. 따라서 $W_{hh}$, $W_{xh}$, $b$ 총 세가지를 'Gradient Descent Algorithm'을 이용하여 최적화하게 되고, 이 과정에서 'Back Propagation'이 이용됩니다.
중요한 점은 위 그림에서 $W_{hh}$, $W_{xh}$, $b$가 네 개있는 거처럼 보이지만 실제로는 12개의 값이 아닌 3개의 변수라는 점입니다.
Back Propagation에 대한 개념은 아래 포스팅에 자세히 설명되어있습니다.
https://box-world.tistory.com/19
[머신러닝] Back Propagation(역전파) 정복하기
시작하며 오늘은 머신러닝에서 가장 큰 고비 중 하나인 ' Back Propagation(역전파) 알고리즘' 에 대해 공부해보겠습니다. 알고리즘을 이해하기 어려울 수도 있고, 복잡한 수식이 나와 거부감이 드실
box-world.tistory.com
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [ 핸즈온 머신러닝 2판 ] Linear Regression 속 Regularization이란? (0) | 2020.09.30 |
|---|---|
| [머신러닝 순한맛] CNN(Convolutional Neural Network)란? (0) | 2020.05.25 |
| [머신러닝 순한맛] 다변량 정규분포(Multivariate Gaussian Distribution) in 이상 탐지(Anomaly Detection) (1) | 2020.05.24 |
| [머신러닝 순한맛] 이상 탐지(Anomaly Detection) vs Classification in Supervised Learning (0) | 2020.05.24 |
| [머신러닝 순한맛] 이상 탐지(Anomaly Detection)이란? (8) | 2020.05.22 |