"이끌거나, 따르거나, 비켜서라."
- Ted Turner (CNN 설립자) -
4.5 선형 모델(Linear Model)에서의 규제(Regularization)
Regularization은 모델이 Overfit되었을 때, 이를 감소시키는 대표적인 방법입니다. 다항 회귀(Polynomial Regression)에서는 단순히 차수를 감소시키는 것으로 Regularization이 가능합니다.
선형 회귀(Linear Regression)에서는 모델의 가중치를 제한하여 Regulariztion이 이뤄집니다. 여기에서 세 가지 방법이 있는데 이제부터 하나하나 살펴 보겠습니다.
4.5.1 릿지 회귀(Ridge Regularization)
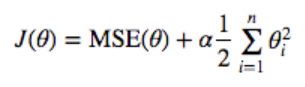
Linear Regression에 Regularization 항이 추가된 것이 Ridge regression입니다. Regularization 항은 훈련하는 동안에만 Cost 함수에 존재하고, 성능을 평가할 때는 포함하지 않습니다. 위 식이 어떻게 Overfit을 억제하는 것일까요?
우선 $θ$는 가중치입니다. 기본적으로 우리는 Cost가 최소가 되길 원합니다. 그런데 Regularization으로 인해 기존보다 $θ_i^2$들이 더해졌습니다.
그러면 모델을 학습시키는 입장에서는 Cost를 최소화하기 위해 $θ_i$를 기존보다 더 작게 설정해야할 것입니다. 그렇게 하면 보통 높은 차수에 곱해지는 가중치 $θ_i$는 0에 가까워져 없어지면서 차수가 내려가게 되면서 Overfit을 막게 됩니다.
하이퍼파라미터 $α$는 모델을 얼마나 Regularization할지 결정합니다. 이것이 커지면 커질수록 추가로 더해지는 가중치의 총합은 커지기 때문에 모델 학습이 이 가중치를 더욱 낮게 설정하려 하면서 차수가 더욱 낮아질 것입니다.
반대로 $α$가 0이라면 기존에 우리가 알던 Cost함수와 동일해집니다. 다음은 $α$의 변화에 따른 Ridge Regression의 훈련 결과입니다.
from sklearn.linear_model import Ridge
def plot_model(model_class, polynomial, alphas, **model_kargs):
for alpha, style in zip(alphas, ("b-", "g--", "r:")):
model = model_class(alpha, **model_kargs) if alpha > 0 else LinearRegression()
if polynomial:
model = Pipeline([
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("std_scaler", StandardScaler()),
("regul_reg", model),
])
model.fit(X, y)
y_new_regul = model.predict(X_new)
lw = 2 if alpha > 0 else 1
plt.plot(X_new, y_new_regul, style, linewidth=lw, label=r"$\alpha = {}$".format(alpha))
plt.plot(X, y, "b.", linewidth=3)
plt.legend(loc="upper left", fontsize=15)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 3, 0, 4])
plt.figure(figsize=(8,4))
plt.subplot(121)
plot_model(Ridge, polynomial=False, alphas=(0, 10, 100), random_state=42)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(122)
plot_model(Ridge, polynomial=True, alphas=(0, 10**-5, 1), random_state=42)
save_fig("ridge_regression_plot")
plt.show()아래 그래프에서 왼쪽은 일반적인 Linear model, 오른쪽은 Polynomial Regression으로 데이터를 10차로 확장한 후 Regularization을 적용하였습니다.

Ridge Regression의 최적화는 Linear Regression과 마찬가지로 경사 하강법(Gradient Descent Algorithm)과 정규 방정식(Normal Equation)이 모두 적용가능합니다. 다음은 Ridge Regression에서 Normal Equation을 적용하는 방법입니다.

다음은 sklearn에서 Normal Equation을 이용하여 Ridge Regression을 최적화하는 코드입니다.
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky", random_state=42)
ridge_reg.fit(X, y)
ridge_reg.predict([[1.5]])
>> array([[1.55071465]])다음은 SGD(확률적 경사 하강법)을 사용하여 최적화한 코드입니다.
sgd_reg = SGDRegressor(penalty="l2", max_iter=1000, tol=1e-3, random_state=42)
sgd_reg.fit(X, y.ravel())
sgd_reg.predict([[1.5]])
>> array([1.47012588])
4.5.2 라쏘 회귀(Lasso Regression)

Lasso Regression과 Ridge Regression의 차이점은 Regularization 항에서 나옵니다. 이것을 마찬가지로 Linear Regression과 Polynomial Regression에 적용해보겠습니다.
from sklearn.linear_model import Lasso
plt.figure(figsize=(8,4))
plt.subplot(121)
plot_model(Lasso, polynomial=False, alphas=(0, 0.1, 1), random_state=42)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(122)
plot_model(Lasso, polynomial=True, alphas=(0, 10**-7, 1), random_state=42)
save_fig("lasso_regression_plot")
plt.show()
Lasso Regression은 가장 큰 특징은 중요하지 않은 feature는 제거해버린다는 것입니다. 위 그래프에서 $α = 1e - 07$일 때 그래프가 거의 선형적인 이유가 바로 중요하지 않은 feature의 가중치들이 모두 0이 되었기 때문입니다.
즉 Lasso Regression은 자동으로 중요한 feature들을 선택하고 나머지 가중치들은 0으로 만들고, 선택된 feature의 가중치들도 상대적으로 적은 희소 모델(sparse model)을 만든다.
다음은 sklearn에서 Lasso Regression을 적용한 코드입니다.
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
lasso_reg.predict([[1.5]])
>> array([1.53788174])
4.5.3 엘라스틱넷(elastic net)
Elastic net은 Ridge와 Lasso를 섞은 모델입니다. 말 그대로 Ridge와 Lasso의 Regularization 항을 모두 더하고, 그 혼합 비율을 $r$을 사용해 조절합니다.
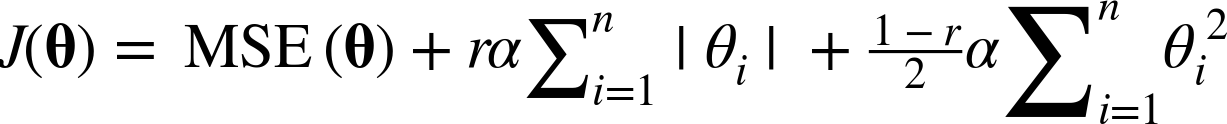
지금까지 Overfit을 막기 위해 사용하는 세가지 Regularization 방법에 대해 알아보았습니다. 대부분의 경우 약간의 Regularization은 무조건 필요하기 때문에 Regularization이 없는 Linear Regression은 지양해야합니다.
보통 Regularization이라고 하면 Ridge가 기본이 되지만, 많은 feature들 중 일부 feature만 중요하게 사용된다면 Lasso나 Elastic을 사용하는 것이 좋습니다. 왜냐하면 Lasso는 앞서 말한대로 중요하지 않은 feature의 가중치는 0으로 만들기 때문입니다.
그리고 feature의 수가 data의 수보다 많거나, 특정 feature 몇개가 강하게 연관되어있다면, Lasso보다는 Elastic을 사용하는 것이 좋습니다. 다음은 sklearn에서 Elastic net을 사용한 코드입니다.
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5, random_state=42)
elastic_net.fit(X, y)
elastic_net.predict([[1.5]])
>> array([1.54333232])
4.5.4 조기 종료(Early Stopping)
Gradient Descent Algorithm을 Regularizatin하는 방법은 Cost가 극솟값에 도달하면 훈련을 중지하는 것입니다.

Batch-Gradient Descent로 훈련시킨 위 모델은 Epoch가 늘어날수록(훈련이 반복될수록) Cost가 점점 줄어들다가 다시 상승합니다. 즉 다시 상승하는 이 지점이 Overfit의 분기점입니다. 따라서 이 지점에서 멈추면 훈련 과정에서 Overfit되는 것을 막을 수 있습니다. 다음은 조기 종료를 위한 구현 코드입니다.
from copy import deepcopy
poly_scaler = Pipeline([
("poly_features", PolynomialFeatures(degree=90, include_bias=False)),
("std_scaler", StandardScaler())
])
X_train_poly_scaled = poly_scaler.fit_transform(X_train)
X_val_poly_scaled = poly_scaler.transform(X_val)
sgd_reg = SGDRegressor(max_iter=1, tol=-np.infty, warm_start=True,
penalty=None, learning_rate="constant", eta0=0.0005, random_state=42)
minimum_val_error = float("inf")
best_epoch = None
best_model = None
for epoch in range(1000):
sgd_reg.fit(X_train_poly_scaled, y_train) # 중지된 곳에서 다시 시작합니다
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
val_error = mean_squared_error(y_val, y_val_predict)
if val_error < minimum_val_error:
minimum_val_error = val_error
best_epoch = epoch
best_model = deepcopy(sgd_reg)이번 포스팅은 여기서 마치겠습니다. 긴 글 읽어주셔서 감사합니다. 행복한 하루 보내시길 바랍니다 :)
'AI > Coursera ( Machine Learning )' 카테고리의 다른 글
| [머신러닝 순한맛] 순환 신경망(RNN)이란? (3) | 2020.05.27 |
|---|---|
| [머신러닝 순한맛] CNN(Convolutional Neural Network)란? (0) | 2020.05.25 |
| [머신러닝 순한맛] 다변량 정규분포(Multivariate Gaussian Distribution) in 이상 탐지(Anomaly Detection) (1) | 2020.05.24 |
| [머신러닝 순한맛] 이상 탐지(Anomaly Detection) vs Classification in Supervised Learning (0) | 2020.05.24 |
| [머신러닝 순한맛] 이상 탐지(Anomaly Detection)이란? (8) | 2020.05.22 |