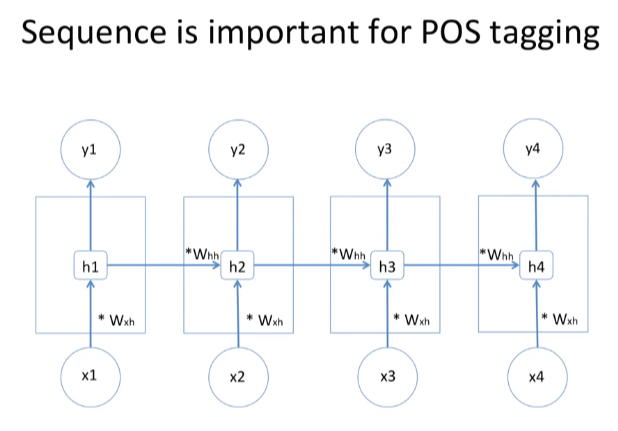
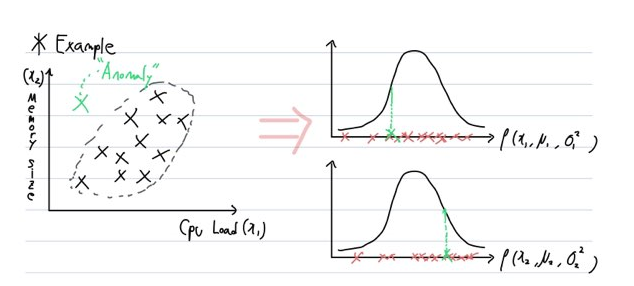
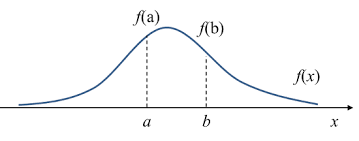
이번 포스팅에서는 머신러닝 공부의 Hello World! 라고 부르는 데이터셋인 MNIST를 사용하여 분류(Classification) 작업을 하는 모델을 만들어보고자 합니다. 이번 포스팅은 아래 포스팅을 공부하시고 보시면 더욱 효과적입니다. https://box-world.tistory.com/24 [머신러닝] 머신러닝 시스템 디자인 하기 : Precision, Recall, F score 시작하며 머신러닝 시스템을 디자인하면서 적용해볼 수 있는 방법들은 다양하게 존재합니다. 이번 포스팅에서는 여러 방법들 중에 하나의 최선의 방법을 골라 적용할지 판단하는 체계적인 방�� box-world.tistory.com 3.1 MNIST MNIST 데이터셋은 고등학생과 미국 인구조사국 직원들이 손으로 쓴 7000..